DeepSeek Sparse Attention from First Principles
FLOPs, dollars and a path to million-token context window

What sets the DeepSeek team apart among the recent wave of Chinese foundation model labs is the outsized impact of their innovations in model architecture and training. No other team comes close in the breadth of novel techniques the “Whale team” has introduced over the past 24 months. In this text, we conduct a technical deep dive into DeepSeek Sparse Attention (DSA) - the attention mechanism responsible for massively driving down the cost of running the most recent DeepSeek models, especially at long context. This text proceeds as follows:
First, we recall how Group Query Attention works. We show how KV cache scales with the number of tokens in the batch. As we increase the batch size, KV cache quickly becomes the bottleneck, throttling the inference throughput (tokens per second).
Second, we investigate the crucial element of DSA - the Multi-Head Latent Attention (MLA). We explain where the performance gains come from (KV cache compression), we derive a theoretical model, and we compare it with real-world performance on Hopper GPUs with kernels from SGLang.
Last but not least, we cover how DSA itself works. At a high level, DSA reduces the number of tokens each query attends to - similar in spirit to Sliding Window Attention (SWA), but with a crucial difference. SWA attends to a fixed window of the most recent tokens, discarding older context entirely. DSA keeps the full context accessible and uses a lightweight indexer to select the most relevant tokens from anywhere in the sequence. The full MLA attention then runs only over this selected subset. The downside is that we still need to store the full KV cache, but the upside is that empirically it yields far better performance than position-based approaches.
Based on these observations, we speculate about the business implications of DSA - specifically, how it enables “Claude Code-like” products to be viable and profitable at long contexts. We discuss Z.ai’s pricing strategy for the GLM Coding Plan, and mention works building on DSA that could enable even cheaper long-context capabilities.
Introduction
DeepSeek revolutionized the attention mechanism with MLA introduced in DeepSeek V2 back in May 2024. They’ve shown you can compress the keys and values cache into a single compressed representation without sacrificing the performance of the model. The same attention mechanism was later adopted in DeepSeek V3 and R1 that made the DeepSeek team famous. Surprisingly, MLA has been adapted by relatively few competitor models, with notable examples being Kimi K2 adopting MLA and, more recently, GLM 5 adopting DSA.
With DeepSeek 3.2, they introduced DeepSeek Sparse Attention (DSA) - optimizing attention further. It achieves near-constant decode time and O(S) prefill, driving down the cost with apparently little to no degradation to performance (e.g., see how well DS 3.2 performs in long-context eval by AA). Figure 1 demonstrates the cost of prefill and decode with sequence length as measured by DeepSeek; later throughout this text we will reference these figures and show how closely we managed to reproduce them.
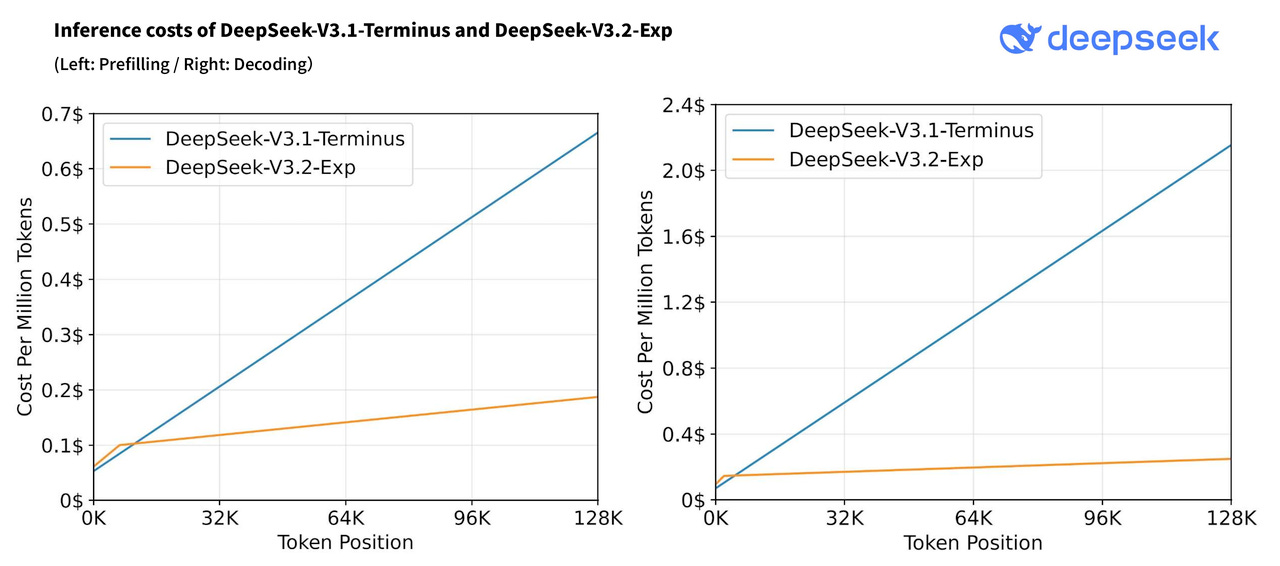
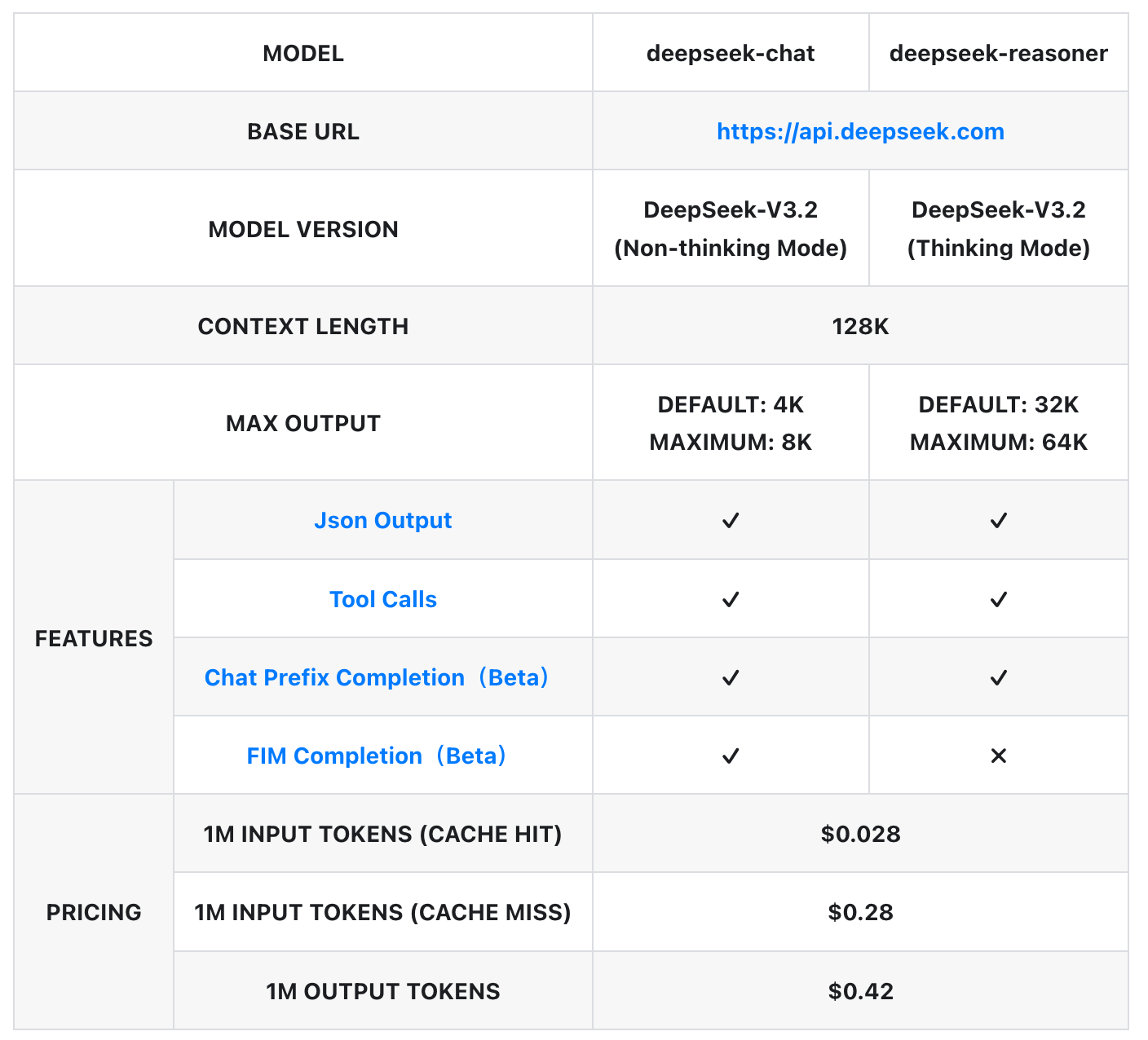
DSA enabled DeepSeek to drive down the price of the API to only 42 cents per million output tokens, fueling the intelligence involution race (see Fig. 2 demonstrating DS pricing).
To fully enjoy this article, the reader needs some prior knowledge: what it means to be compute/memory bound, what a FLOP is, the difference between prefill and decode, etc. If these topics are new, we recommend reading the seminal tensoreconomics text first:

Group Query Attention
Before we introduce MLA, let’s take a look at “vanilla” multi-head attention. At the core of it is the attention equation. This computation is executed independently for each attention head.
Where:
After we calculate this for each attention head, we concatenate across the head_dim dimension and multiply the result by the Wo projection matrix.
The prefill computation couldn’t be more straightforward. We present an example forward pass of MHA in Figure 3.
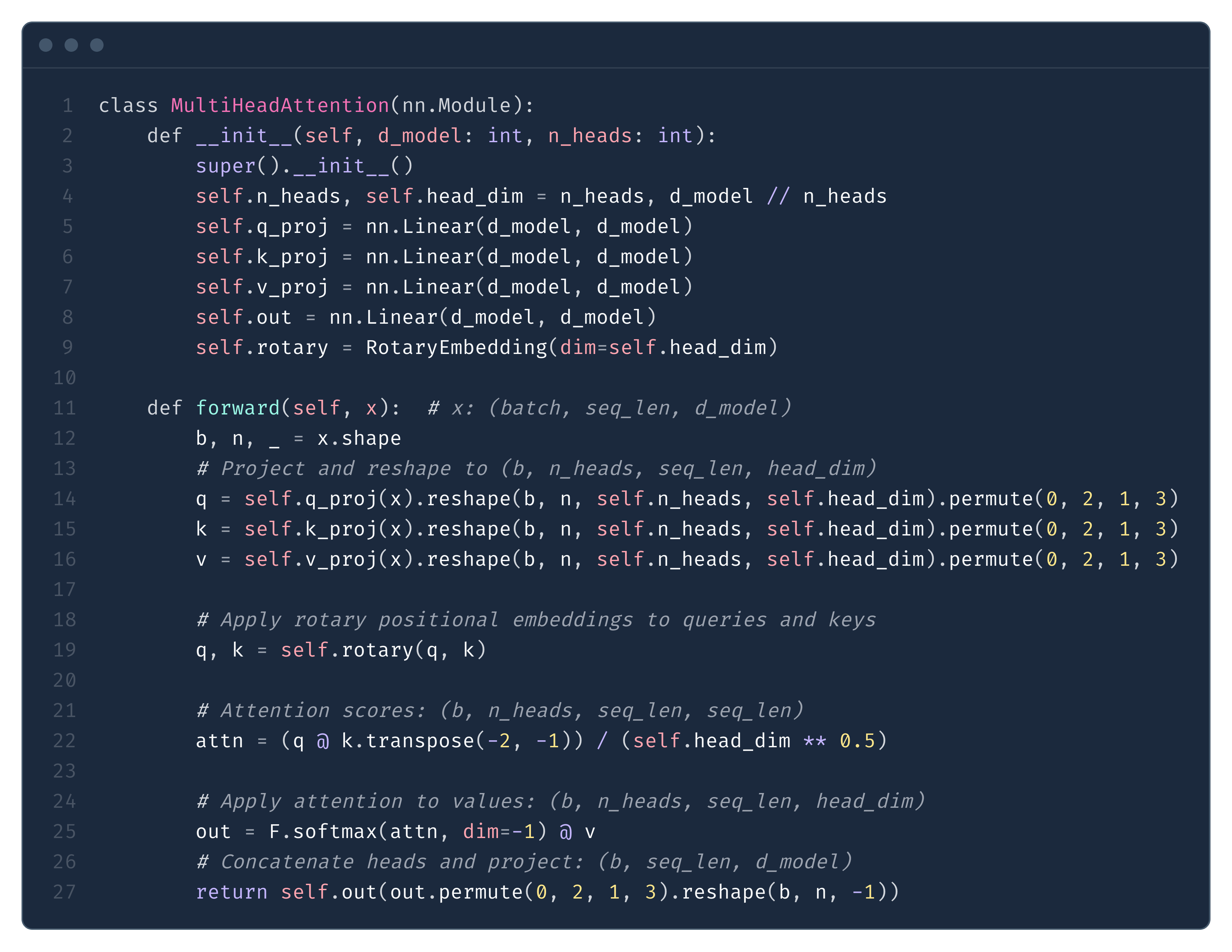
As we have shown in the formative article of tensoreconomics, prefill is primarily compute-bound, meaning we spend most time actually running the computations (we do large-scale matrix multiplications) - hence the FLOPs will determine the runtime. We can estimate the self-attention prefill FLOPs as:
Since all attention is causal, each token attends only to itself and prior tokens — the exact count is S(S+1)/2 pairs, which we approximate as S²/2 for large S. The
W_oprojection is applied to every token unconditionally, so it is unaffected.
To make our calculations in this section more concrete, we will be using Llama 3.3 as an example. For parameter names, we follow the Hugging Face config. For further details see Fig. 4.
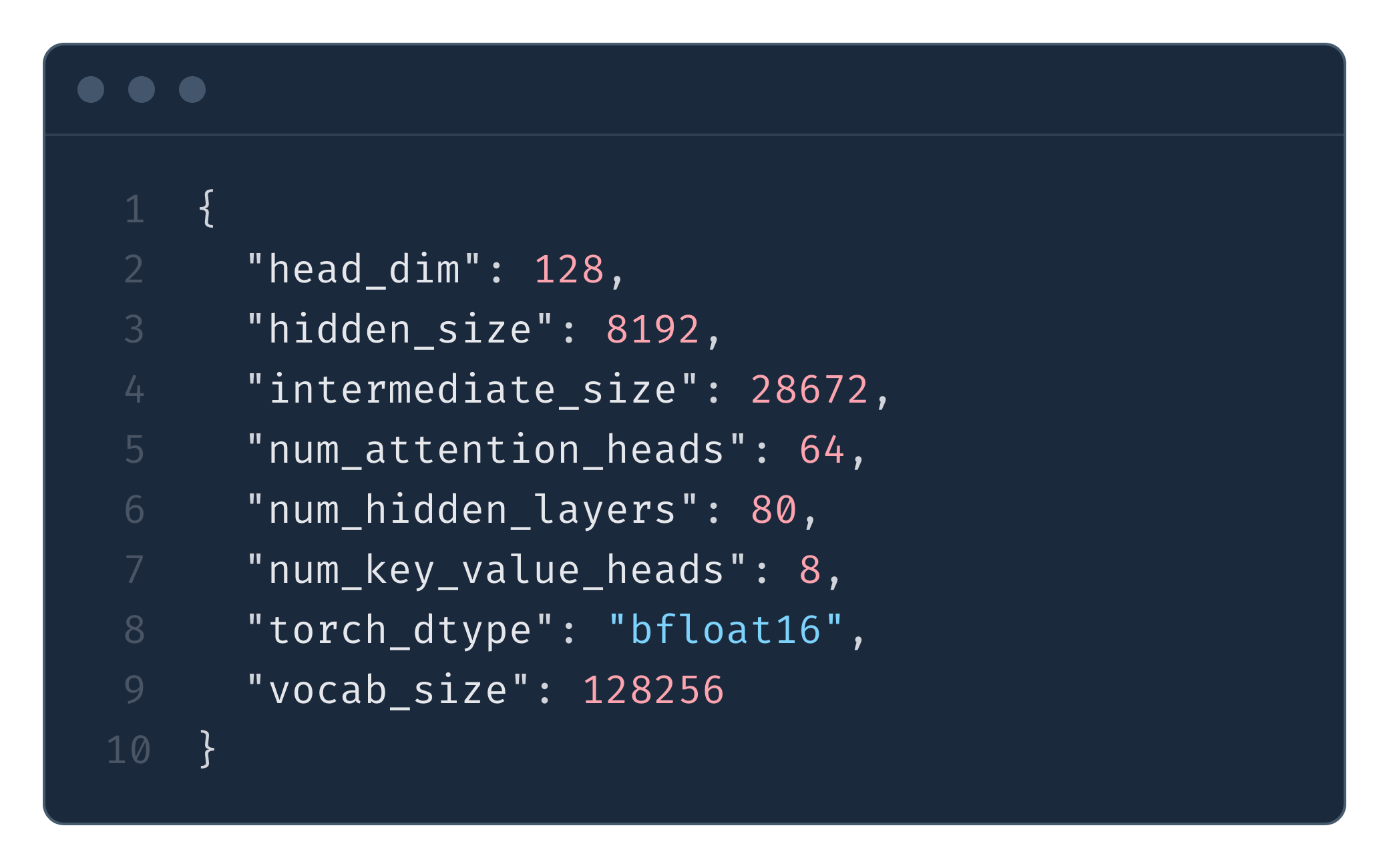
In Fig. 5 we present the results of an experiment showing how the latency of an attention layer forward pass increases as we scale batch size and the sequence length. Notice how the time (because of the underlying FLOPs increase) of the forward scales quadratically with sequence length but linearly with the batch size. It is consistent with Eq. (2), where we can see that the FLOPs scale with S², and since prefill is compute-bound, so should the latency.
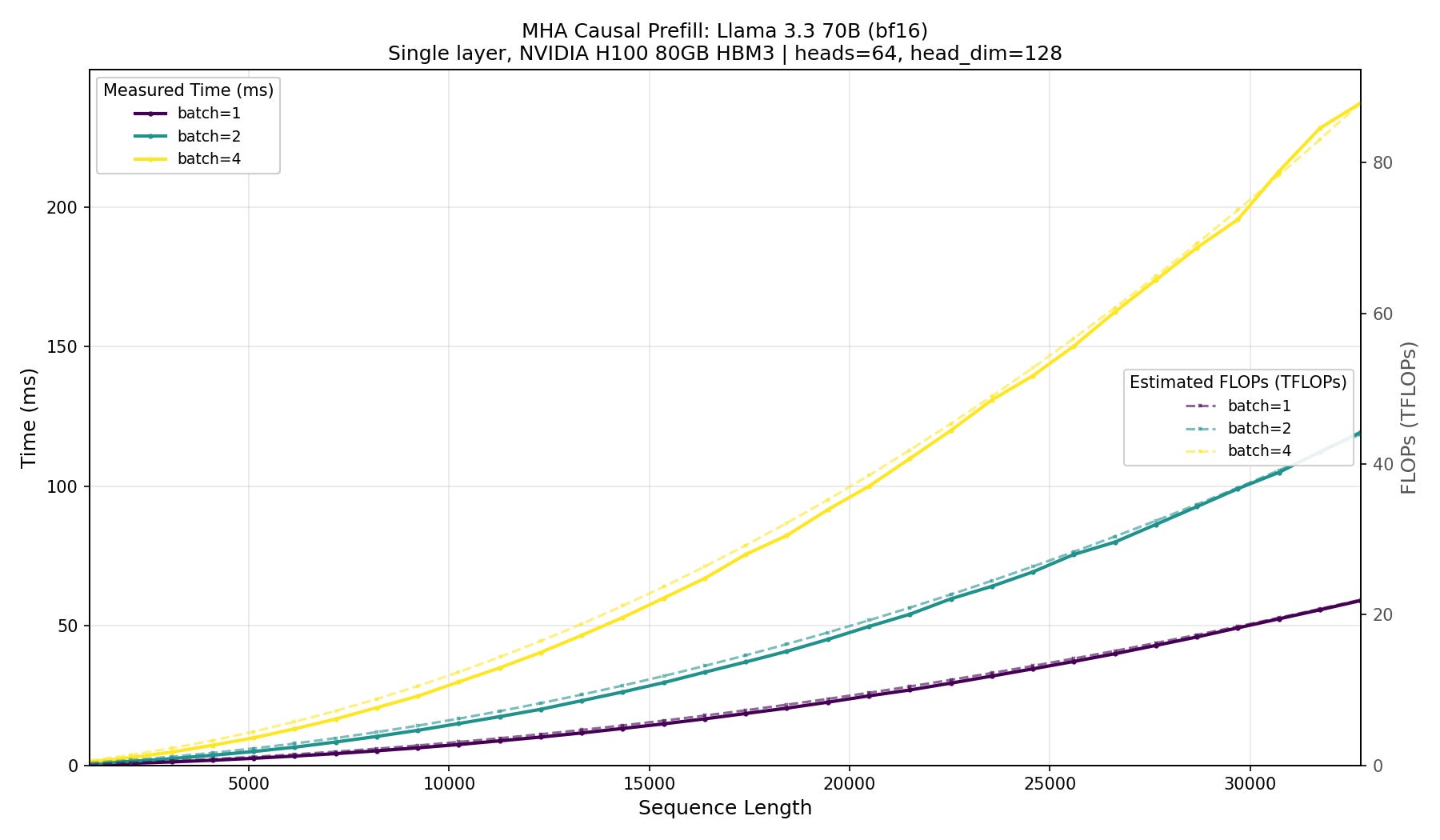
scaled_dot_product_attention.Note how GPU compute (FLOPS) is a good predictor of latency. H100 offers ~989 TFLOPS, and we can estimate the latency as:
For an attention operation, we get a consistent ~43% MFU across different batch sizes and sequence lengths. For example, at batch=4 and S=8192, the causal attention totals 8.8 TFLOPs.
basically the exact time we observe in Figure 5.
This quadratic scaling of prefill will be in stark contrast with decode - in decode, the time of a single forward pass scales linearly with the sequence length. Since in a typical GPU workload decode dominates the wall time, and hence determines the end-to-end inference cost, in this text we will mostly focus on decode.
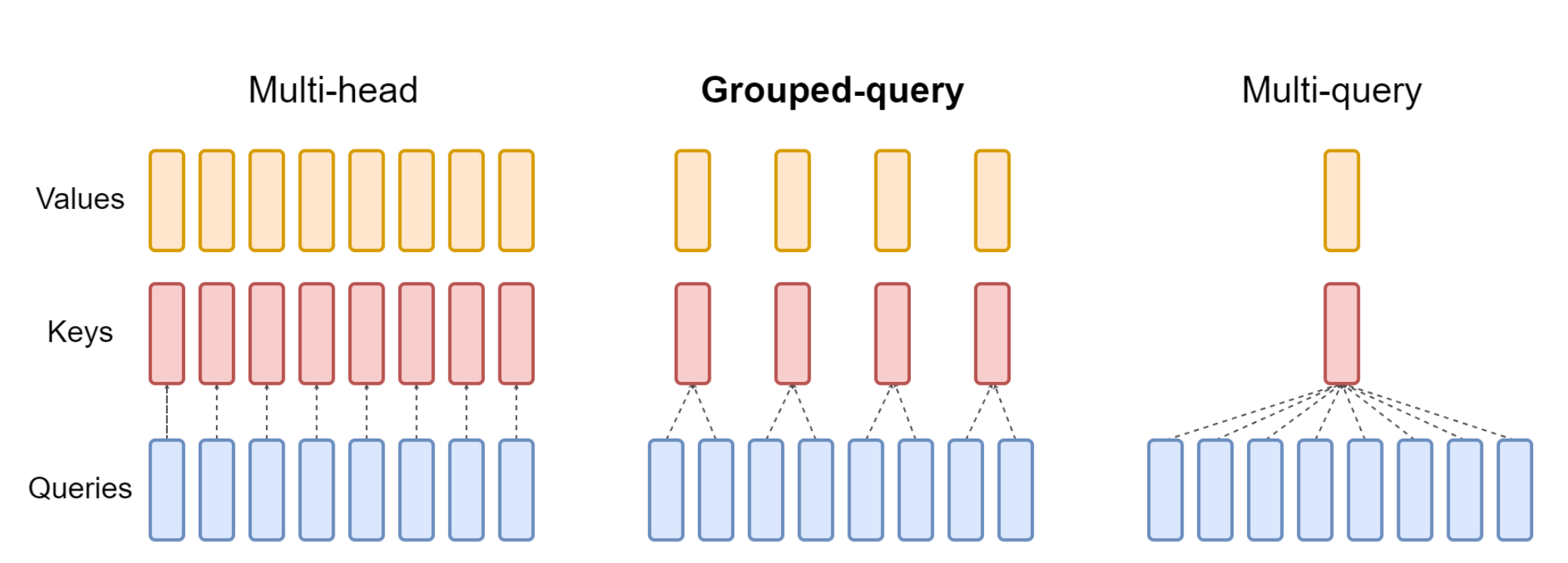
Before we proceed to the decode phase, we need to introduce the concept of Group Query Attention (GQA). GQA was introduced back in 2023 by a team at Google and is considered the de facto standard today for attention-based models. All models you might know, like Llama, Qwen3, gpt-oss and others, use this technique.
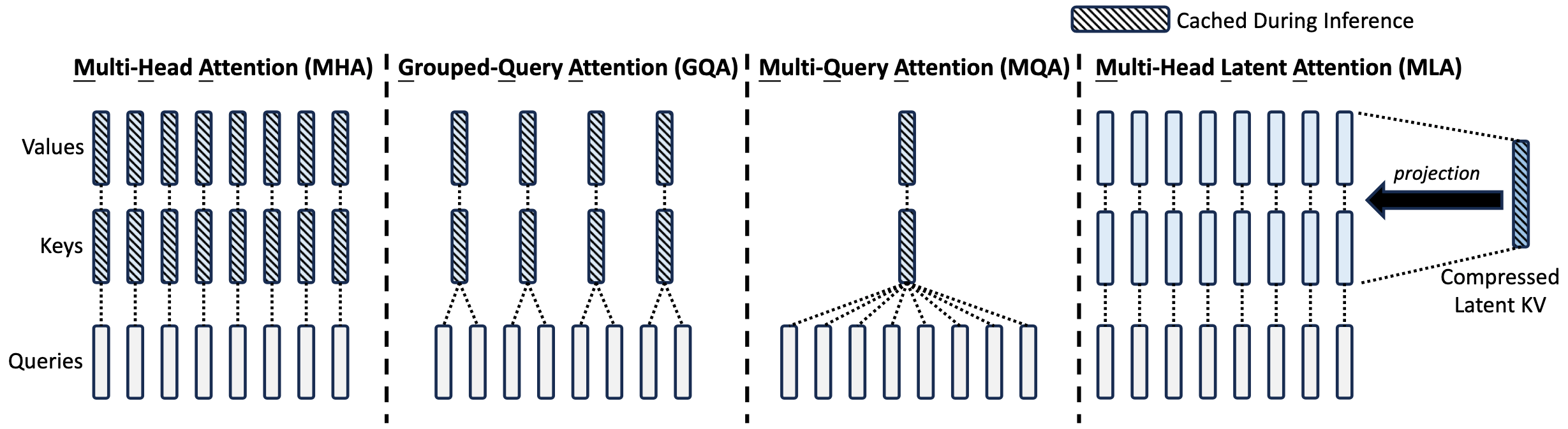
The concept is pretty well captured by the visualisation we present in Fig. 6. GQA reuses single key and value projections across multiple attention heads. As we will show in the next section, it has an enormous impact on the inference speed and, as a result, the cost of producing a token. For this reason, GQA has been largely adopted in the industry and is powering a significant portion of the leading open-source models.
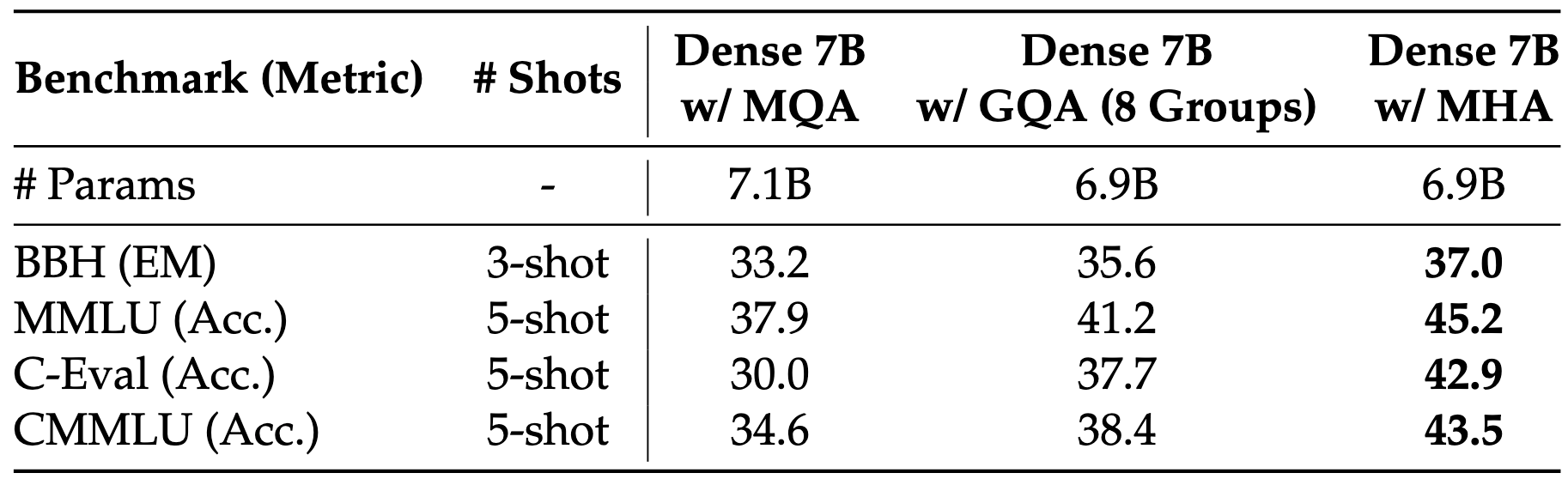
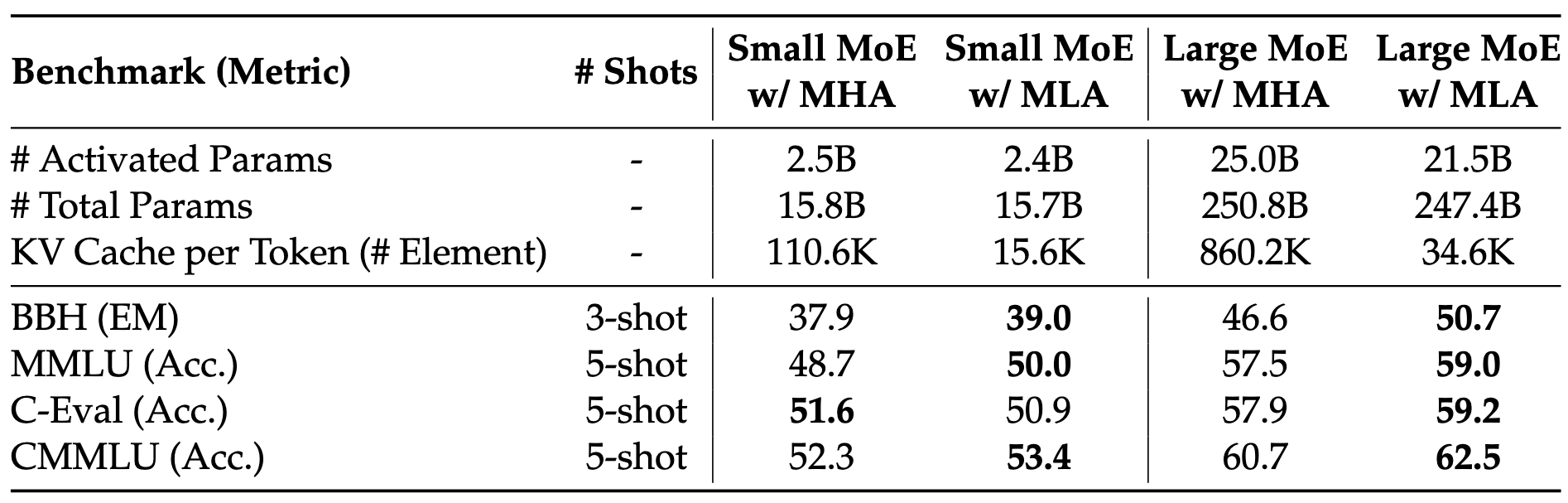
However, there are no free lunches. Using GQA attention comes at a cost of worse end-to-end model performance, as demonstrated in Tab. 1. Even after adjusting for an equal number of parameters, the DeepSeek team showed that using GQA results in a slightly worse performance.
This begs the question: why do people design models with GQA? Why is reducing the number of keys and values cached relevant for reducing the cost of inference?
During the decode, we can cache the keys and values for past tokens and calculate the output only for the new token. The math works similarly to prefill, with an adjustment that now “sequence length” is just 1 (for batch size 1):
We repeat this for each head independently. As you can see visualised in Fig. 7, for this to work we need to save (cache) the k and v values for the past tokens. This scales linearly with the number of tokens in sequence (S).
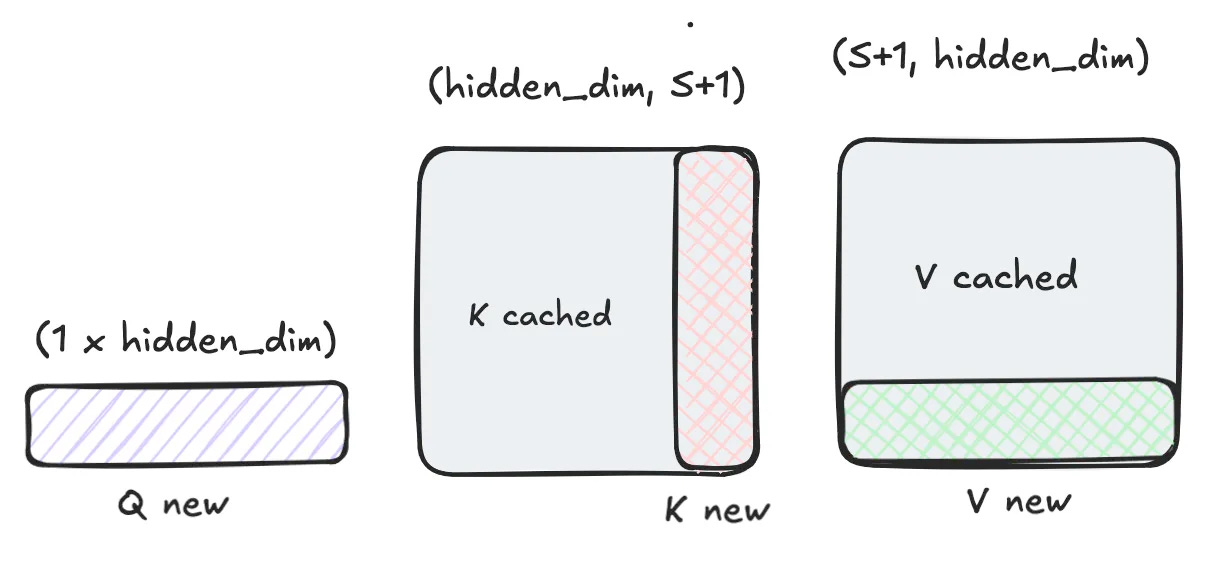
The memory we need to allocate for caching scales as follows:
E.g., for Llama 3.3 70B stored in bf16, this would amount to:
for each token in the sequence (S).
The innovation of GQA is that we reuse a single KV projection between multiple heads. In the HF config (see Fig. 4), this is stored under the num_key_value_heads. Typically there will be far fewer key value heads than the attention heads; e.g., in Llama 3.3 70B, it is 8 key value heads vs 64 attention heads. This means that the memory footprint per token is reduced 8x, which has a significant impact on the inference speed.
As expected, it reduces the size we need to keep per token 8 times:
In Fig. 8 we present a simple implementation of GQA in decode mode. The implementation is very similar to MHA, with the key difference being repeat_interleave, where we repeat the tensors so they can be re-used by multiple attention heads.
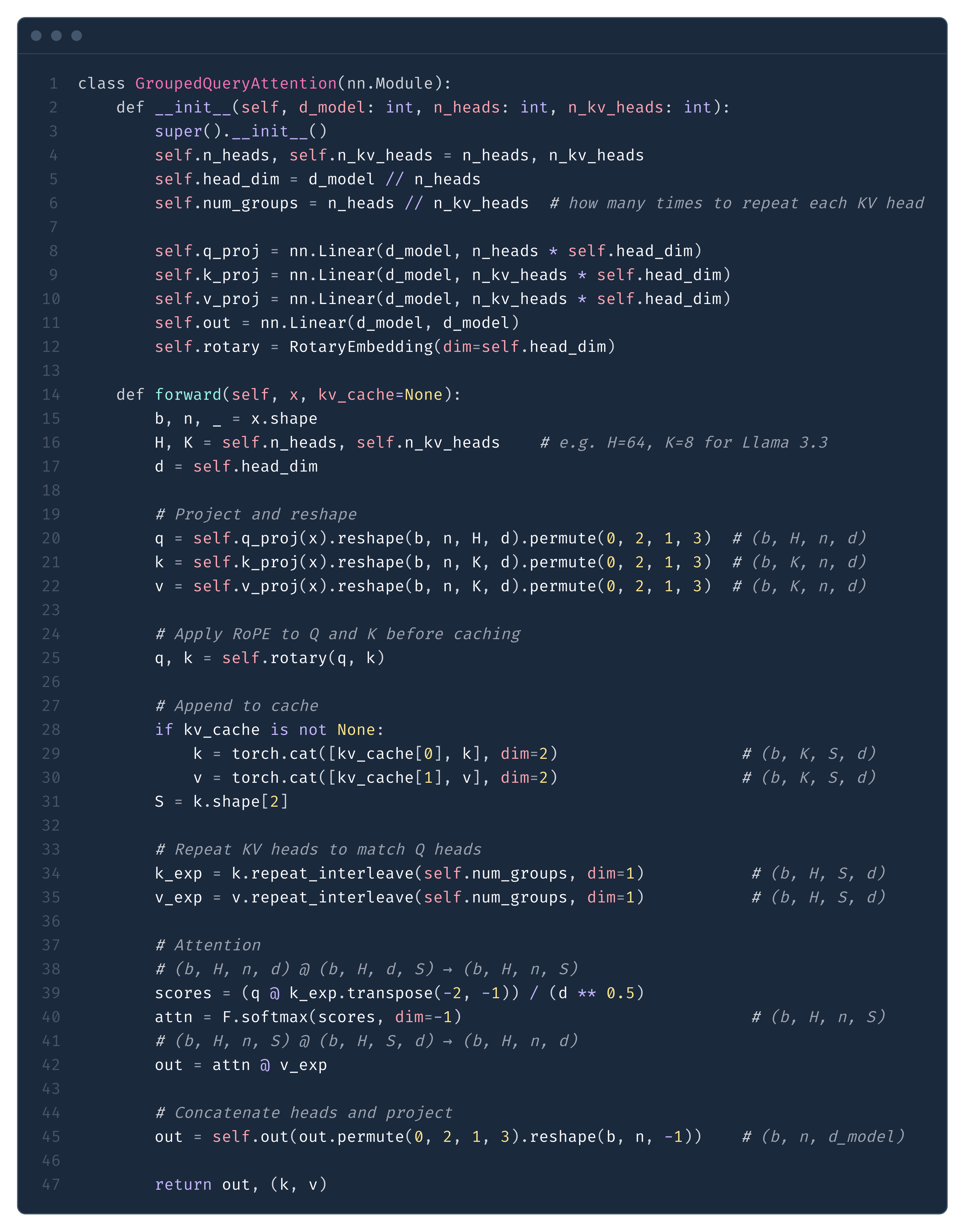
repeat_interleave to match. The KV cache stores separate K and V tensors of size n_kv_heads x head_dim each.Because of KV caching, during decode we move from the matrix-matrix multiplication regime into matrix-vector multiplication. This has an enormous impact on the FLOPs - compare Eq. (6) below with the prefill FLOPs in Eq. (2): the S² term becomes S, scaling down by a factor of S.
This should make intuitive sense - for each new token we need to calculate attention to all previous tokens - O(S) scaling with respect to sequence length. However, as the seasoned readers of our publication will know, now we hit another problem - we get into the low arithmetic intensity regime, and the speed of our program is now limited by the speed of GPU memory, or, in other words, we become memory-bound.
The bottleneck is no longer how fast the GPU can compute but how fast it can load data from HBM (high-bandwidth memory) into the compute units - and this is why the size of the KV cache matters so much for decode performance.
For each transformer layer we have to:
Load the
Wq,Wk,WvandWoprojection matrices.Load the MLP layer (or multiple experts in MoE models).
Load the past KV cache.
All this memory loading will take time, and this time will ultimately determine our cost of serving the model. The issue is, as we increase the combined sequence length, either through processing a longer sequence for one user or via combining multiple requests from multiple users into a single batch request, the size of the KV cache will increase linearly with the number of tokens cached.
The reader should note that, while the size of the KV cache will scale linearly with the batch size, the memory footprint of attention and MLP weights remains constant - we load them once and reuse them across all requests in the batch.
To better illustrate this point, please look at Figure 9. As we increase the combined cached sequence length, at some point the KV cache starts to dominate the memory footprint. Note that this is the memory that GPU(s) needs to load each time we do a forward pass.
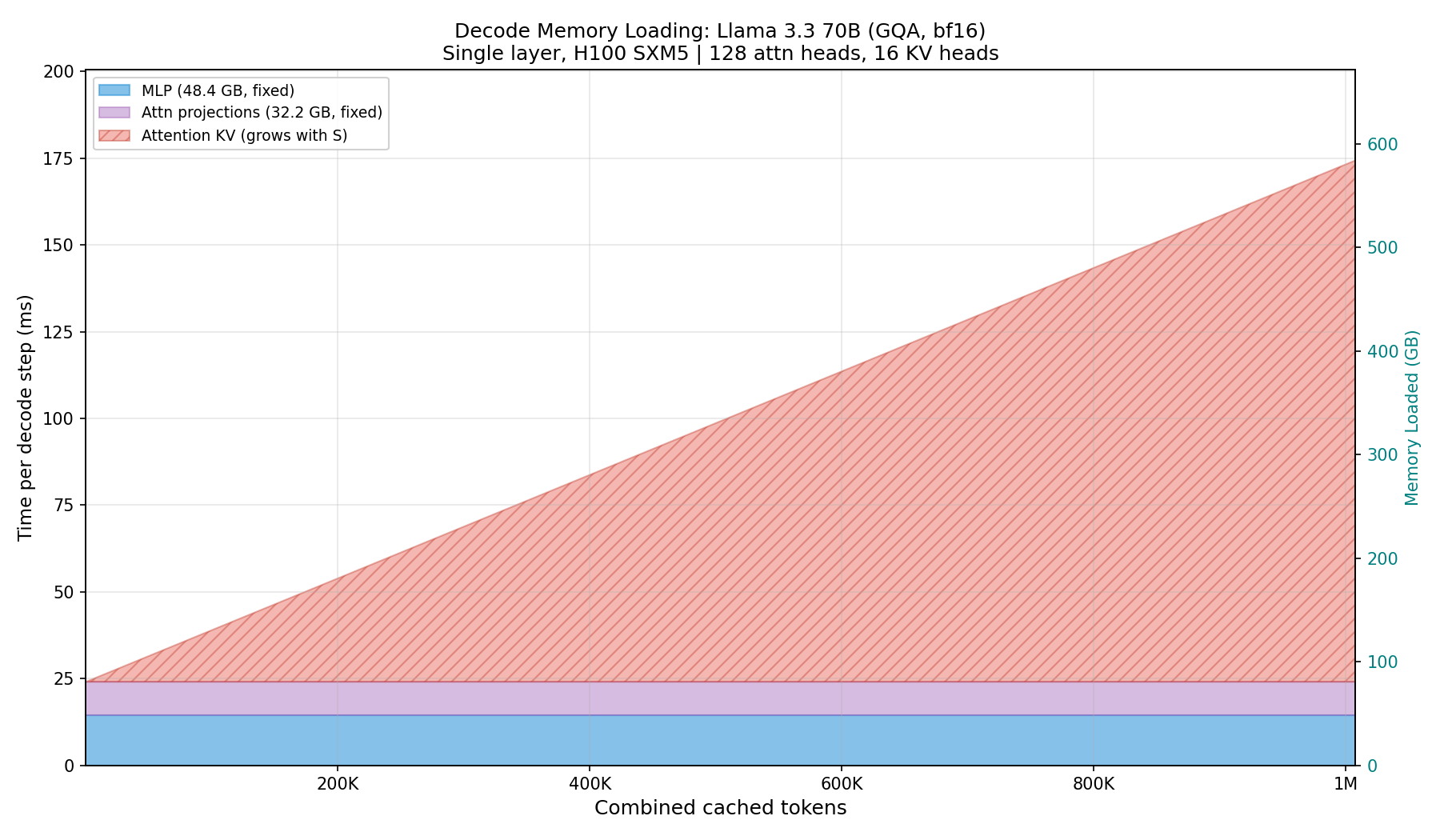
The KV cache growing linearly with the batch size (we store KV for each sequence independently) is the ultimate reason why, as we increase the batch size, the time of a forward pass increases, throttling throughput measured in tokens per second (tps).
This is not just a theoretical argument. In Figure 10 we fix the batch size at 64 and scale the sequence length, measuring the wall time of each component. Note how the measured latency closely follows the shape predicted by the memory loading model in Fig. 9.
The computation in Fig. 10 is for a single layer due to compute constraints (to decrease the complexity, we limited the experiments to a single H100 instance), but the exact same pattern will emerge when we run the actual Llama inference; it will be just repeated by the number of transformer layers.
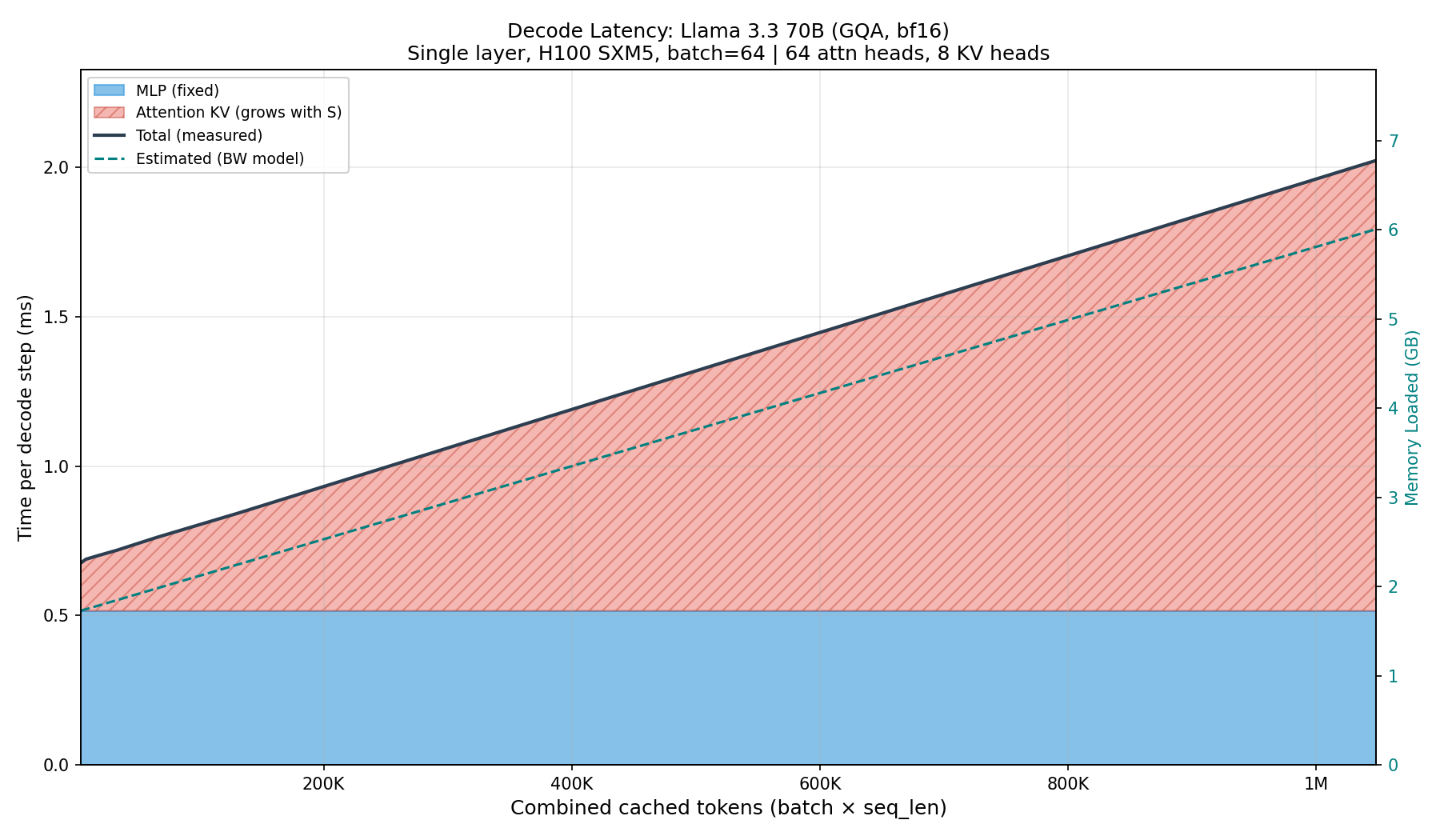
The main intuition the reader should take from reading this section is that for cloud-based inference, where we operate at large batches, the KV cache is becoming the bottleneck throttling the end-to-end throughput (tps). Even though GQA reduces the memory footprint of KV cache, it remains a significant factor limiting the inference speed. The intuitive solution to this problem is to try to compress the size of the KV cache even more, and this is the exact motivation behind Multi-Head Latent Attention.
Multi Head Latent Attention (MLA)
MLA was introduced in May 2024 in DeepSeek V2. The core idea is pretty well captured by Fig. 11 - instead of caching keys and values, why not cache a single compressed (latent) representation for both of them and then simply train two projection matrices to project from latent representation into keys and values? This way we need to store and load during inference significantly less data, speeding up the decode.
In the DeepSeek ablation studies, they show that MLA leads to better end-to-end results than MHA (Tab. 2), while requiring significantly less memory to cache during decode. This is in contrast to GQA, which reduces memory but degrades quality (Tab. 1). According to the DeepSeek V2 paper, this was the main motivation - compress the KV cache to make inference cheaper without compromising model quality.
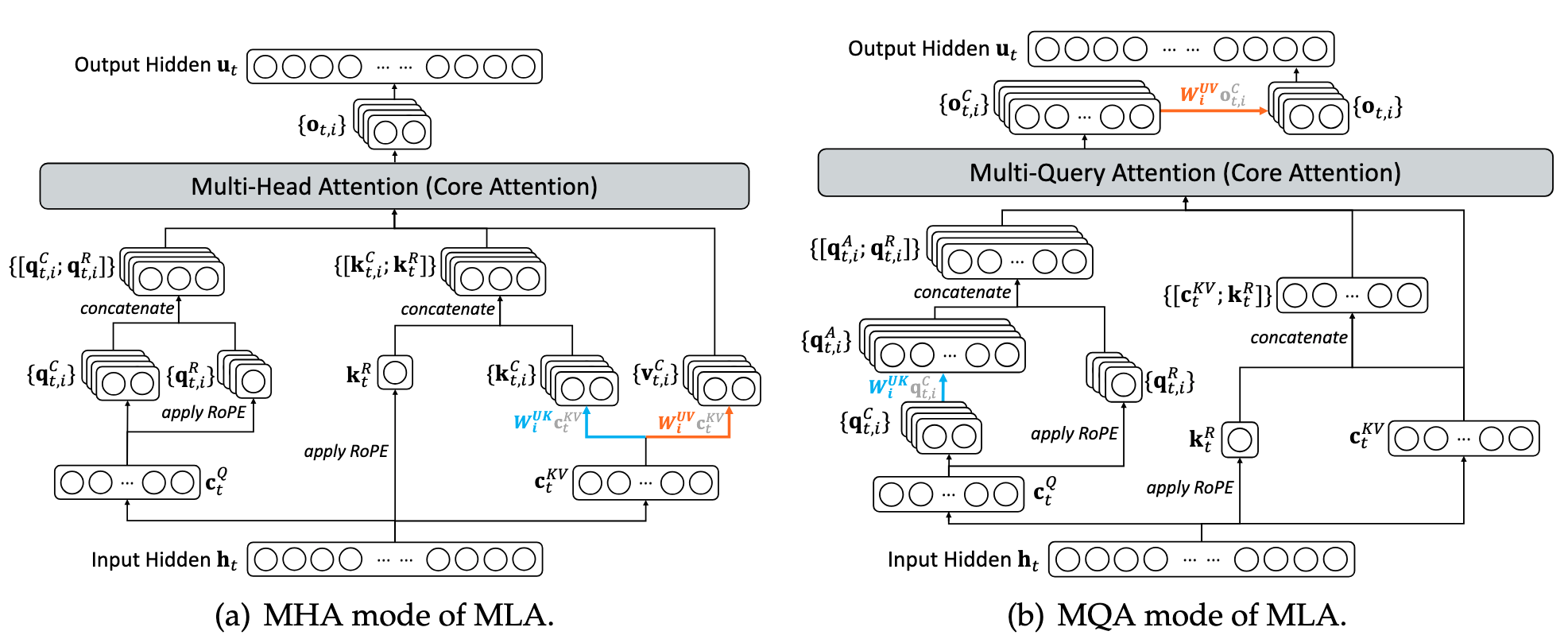
MLA can be executed in two mathematically equivalent modes (Fig. 12): MHA mode and MQA mode. In MHA mode, we reconstruct the full keys and values from the compressed latent and run standard multi-head attention. This minimizes FLOPs, which is what we want during prefill, where we are compute-bound. In MQA mode, we instead absorb the key projection into the query and attend directly to the compressed latent. This spends extra FLOPs, but during decode we are memory-bound anyway, and in return we significantly reduce the memory loaded per step because we only need to pull in the single compressed latent instead of per-head K/V. In the following walkthrough we derive the math for MQA mode that enables fast decode; we discuss why MHA mode is better for prefill in the Appendix.
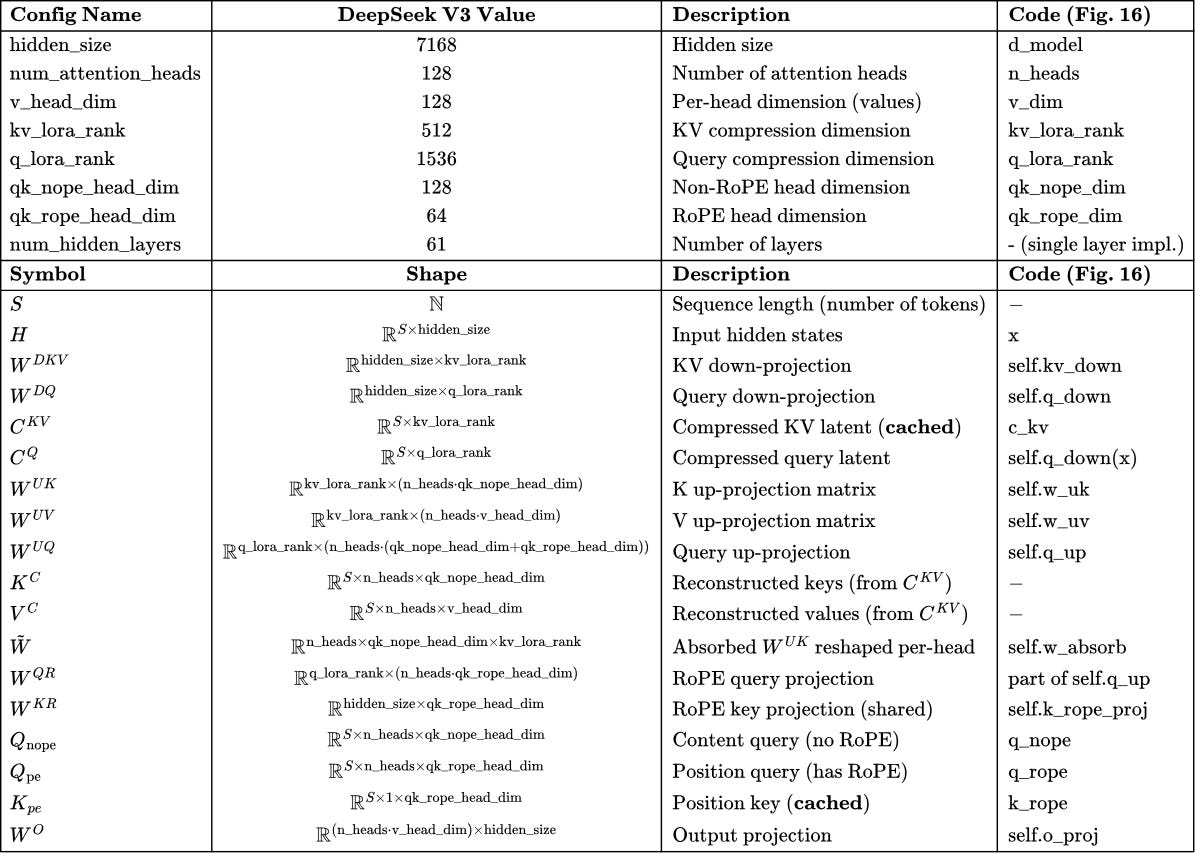
To make it more accessible to the reader, in Tab. 3 we present a high-level summary of all symbols introduced in this section alongside the example values used in the DeepSeek V3 config.
How does MLA work? To see where the savings come from, let’s start from standard attention. Given the input sequence of S tokens:
In normal attention, we have 4 trainable weight matrices
For the attention equation itself, we calculate three projections:
The core idea behind MLA is that instead of caching full keys and values, we compress them into a shared latent representation - and only this representation is cached.
We have a KV down-projection (compression) matrix:
We apply this matrix to H producing a compressed latent matrix
The main benefit of this compression is that kv_lora_rank is significantly smaller than what we’d need to cache storing full keys and values.
E.g., in the case of DeepSeek:
or ~3% of the potential memory footprint had MHA been used.
Keys and values can be reconstructed from C^KV by applying the up-projection matrices W^UK and W^UV:
where:
The algebraic trick: absorbing matrices
Matrix multiplication is associative, meaning:
This allows us to precompute and “absorb” projection matrices, avoiding the need to explicitly reconstruct keys during inference.
We can also compress queries using a down projection matrix:
We apply this matrix to H producing a compressed query latent matrix:
Queries can be reconstructed from the matrix C^Q by applying the up-projection matrix W^UQ:
where:
Note: In DeepSeek config (Fig. 13), q_lora_rank = 1536 while kv_lora_rank = 512, so queries use a larger latent dimension than KV, which makes sense since queries aren’t cached during decode anyway.
Now consider the attention score computation:
or in MLA notation:
Expand the transpose:
We never need to explicitly compute K^C! The up-projection W^UK gets absorbed into a precomputed matrix W~.
This is the key computation advantage that significantly boosts the performance. We calculate W~ only once and reuse for all computations. We multiply it with the compressed query latent matrix and compressed (kv) latent matrix.
Algebraically, the same trick can be applied to values and output projections. After computing attention weights A = softmax(Q^C (K^C)^T), we could compute:
Substituting V^C = C^KV W^UV:
By associativity:
However, unlike the K absorption, this fusion is not done in practice. As shown in Tab. 4, the fused W~^VO would be 3.7x larger than keeping W^UV and W^O separate:

W^UV W^O would eliminate one matmul but increases weight size 3.7x, making it impractical for memory-bound decode.Because of this extra footprint, in practice SGLang and vLLM apply W^UV and W^O as two separate operations after attention. Only the K absorption W~ = W^UQ (W^UK)^T is precomputed at warmup.
The RoPE Problem
Modern LLMs use Rotary Position Embeddings (RoPE), which encode position information by rotating the query and key vectors. The rotation depends on the token’s position in the sequence.
Mathematically, RoPE applies position-dependent rotations
Let’s see what happens when we try to apply the absorption trick with RoPE. If we naively apply RoPE to the reconstructed keys and queries:
Problem: We’re forced to materialize the full K^C = C^KV W^UK in order to apply RoPE to it. The absorption trick no longer works - we can’t precompute W~ = W^UQ(W^UK)^T when RoPE sits in between:
The solution? Decoupled RoPE - split the attention into two parts:
Part 1: Content attention (compressed, no RoPE)
Captures semantic similarity between tokens
Lives in compressed space - absorption works perfectly
Part 2: Position attention (small, has RoPE)
Captures positional relationships
Small additional dimension - compute directly without absorption
Concretely, we split queries and keys into nope (no position embedding) and rope components (Tab. 5):

The nope Part (Content)
The content components come from our compressed latents, exactly as before:
Where:
The absorption trick works perfectly here - no RoPE to get in the way:
The rope Part (Position)
The position components have RoPE applied, so we compute them directly:
Where:
projects to all heads, and:
projects to a single shared key.
Note the asymmetry: Q_pe is computed per-head while K_pe is shared across all heads. This is an intentional design choice by DeepSeek - the shared K_pe is broadcast to all 128 heads during attention computation.
Why this asymmetry? (Tab. 6)

Q_pe allows heads to specialize in positional patterns at no memory cost. Shared K_pe saves 128x on position key cache.This design saves 128× on the position key cache while still allowing heads to specialize in different positional patterns through their per-head Q_pe.
Combined Attention Scores
Conceptually, we can think of queries and keys as concatenations of their nope and rope parts. For each head i:
This means the attention scores decompose additively:
Crucially, we never actually concatenate these tensors. Instead, we compute the two terms separately:
Content scores:
Q_nope,i * K_nope,i^T∈ ℝ^(S × S) - computed via absorption trick usingC^QandC^KVPosition scores:
Q_pe,i * K_pe^T∈ ℝ^(S × S) - computed directly (small and fast)
Both terms produce an S × S matrix per head, so they can simply be added:
This is why MLA is efficient - we never materialize the full K_nope (of shape S x num_attention_heads x qk_nope_head_dim) during decode. The absorption trick lets us go directly from cached C^KV (of shape S x kv_lora_rank) to attention scores.
Putting it all together, in Fig. 13 we present a minimal implementation of MLA decode - the MQA mode in DeepSeek’s terminology. This is the path that runs during token generation, where absorption makes decode memory-efficient. Prefill uses a different path (MHA mode) that reconstructs full K/V and runs standard flash attention - we explain why in the Appendix.
Compare this with the GQA implementation in Fig. 8 - the key differences are:
Compressed KV cache (marker ❶): instead of caching separate K and V tensors of size
n_kv_heads × head_dim, we cache a single compressed latentC^KVof sizekv_lora_rank(Eq. 7) plus a small RoPE key of sizeqk_rope_head_dim. This is the source of MLA’s memory savings.K absorption (marker ❷): instead of reconstructing full keys from
C^KV, we reshapeW^UKper-head and use it to projectq_nopeinto the latent space (Eq. 9). The query then attends directly againstC^KVwithout materializing full keys.Decoupled RoPE (marker ❸): position information is handled separately through small additional dimensions (
qk_rope_head_dim = 64), keeping the absorption trick valid for the content part (Eq. 11).Separate V and O projections (marker ❹): unlike the K absorption, fusing
W^UV W^Owould increase weight size 3.7x, so they remain separate.
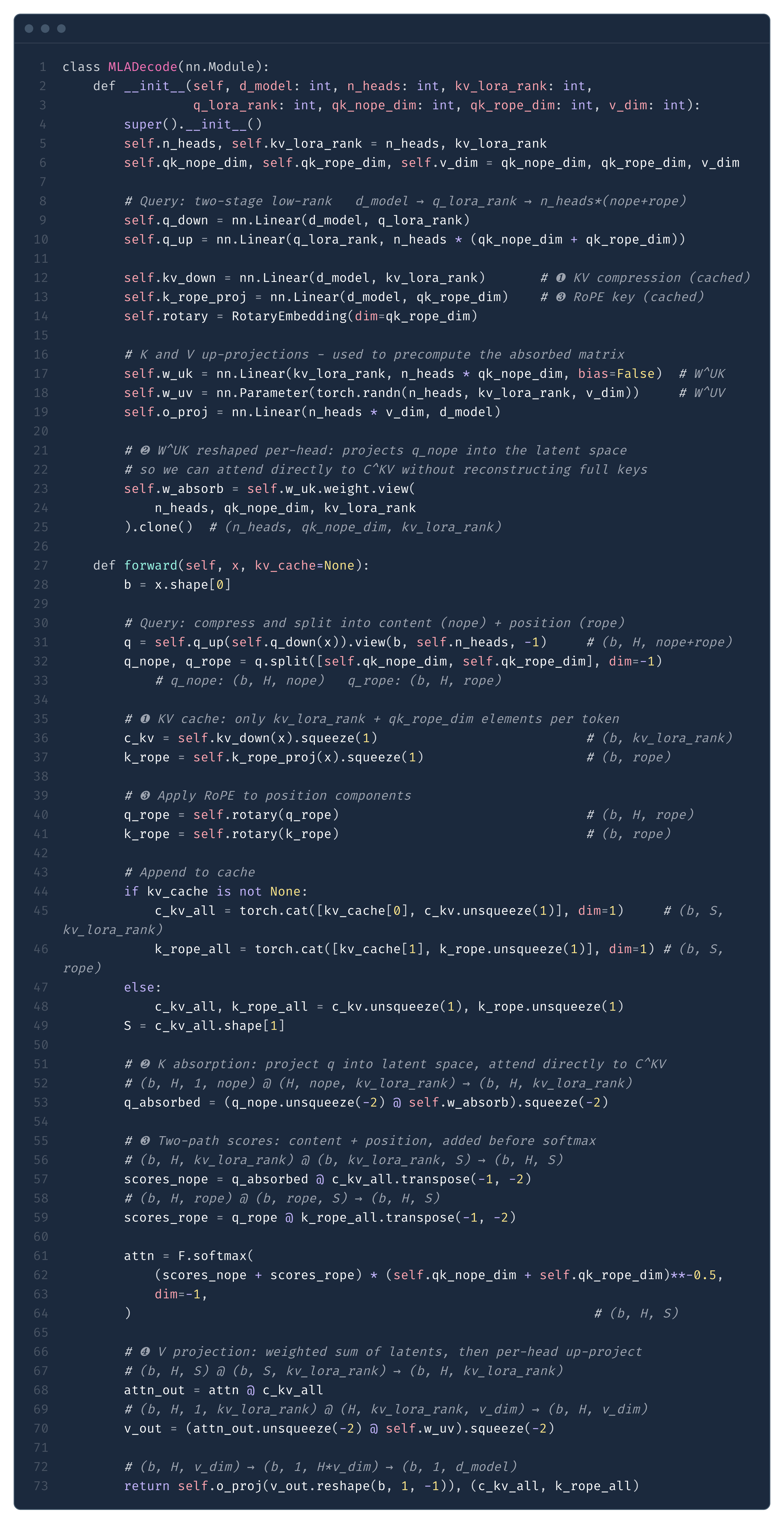
C^KV (kv_lora_rank = 512) and a RoPE key (qk_rope_dim = 64) per token. Attention scores are computed via two paths: content scores through the absorbed matrix w_absorb (marker ❷), and position scores through the RoPE keys (marker ❸). Values are reconstructed per-head from C^KV via w_uv after attention (marker ❹).Note how the KV cache stores only (c_kv, k_rope) - a compressed latent of size kv_lora_rank = 512 plus a small position key of size qk_rope_dim = 64, totalling 576 elements per token. Compare this with GQA which stores separate K and V tensors of size n_kv_heads × head_dim each. The attention computation against C^KV structurally resembles MQA - all 128 heads share the same compressed “key” - which is why MLA’s decode KV cache is so small.
KV Cache Comparison
Let’s now analyse the memory footprint reduction when MLA is used. First, we will calculate the hypothetical memory footprint of KV cache had MLA not been used, then we apply MLA optimizations and show how massively the memory is reduced. For all of the computations in this section, we will apply the numbers from the DeepSeek V3 config (Fig. 14).
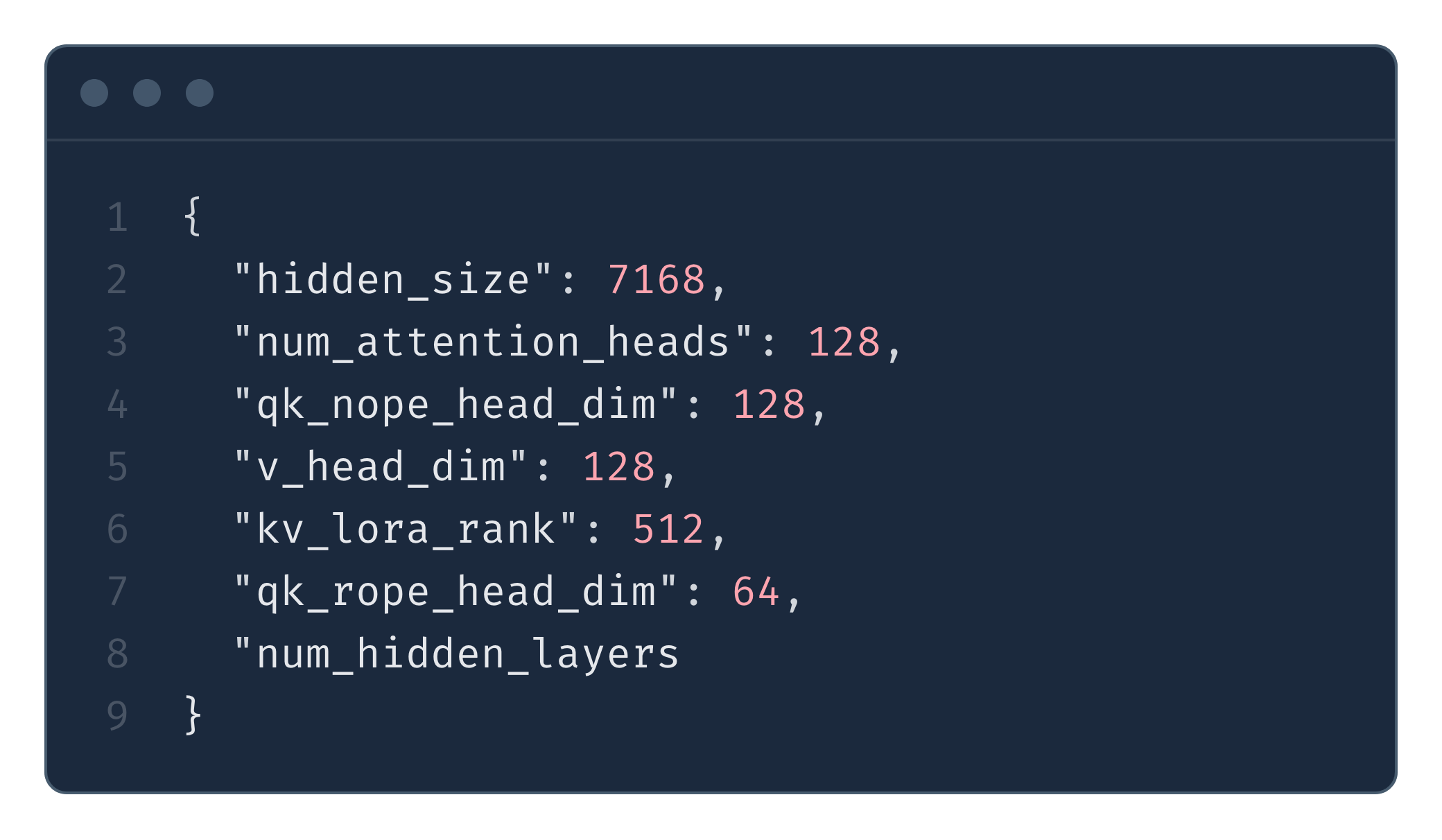
Note: DeepSeek V3’s attention dimensions (
num_attention_heads × head_dim = 128 × 128 = 16384) exceed the model’shidden_size(7168). This is possible because MLA up-projects from compressed latents. For a fair comparison, we compare against hypothetical MHA/GQA with the same attention capacity (128 heads × 128 dimensions).
In Multi-Head Attention, we cache both keys and values for all heads:
In bytes (bf16):
If DeepSeek used GQA with the same ratio as Llama 3 models (8 KV heads for 64 query heads, i.e., 8:1 ratio), that would mean 128 query heads → 16 KV heads:
In bytes (bf16):
With MLA, we only cache the compressed latent C^KV and the position key K_pe:
In bytes (bf16):
We summarize these results in Tab. 7.

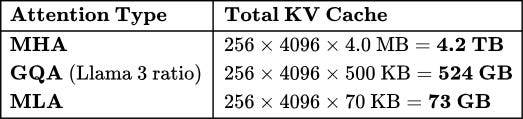
MLA achieves a 57× reduction compared to MHA, and is still 7× smaller than GQA with Llama 3’s ratio.
To put this in concrete terms, Tab. 8 shows the total KV cache at batch size 256 with 4096 cached tokens per request:
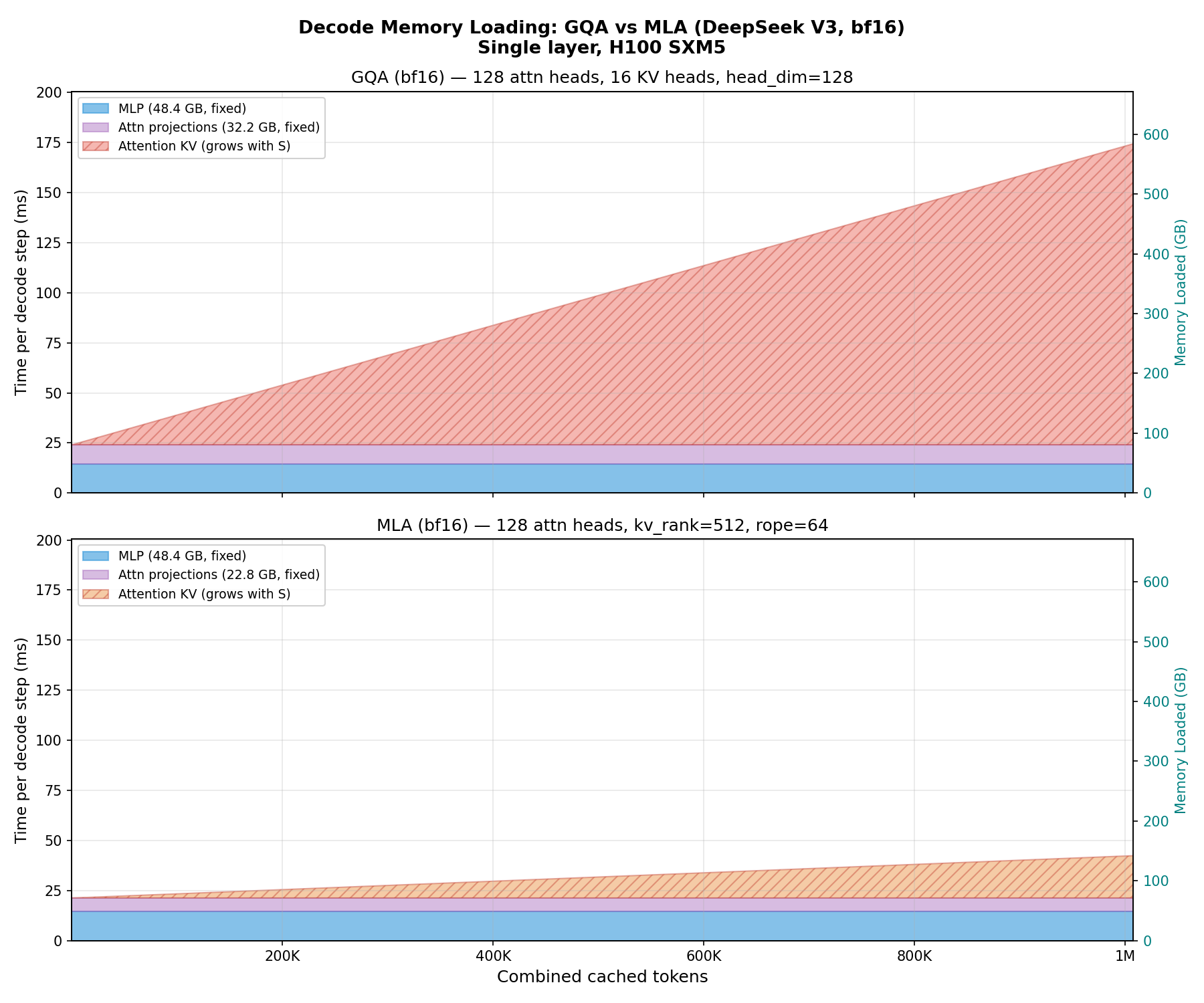
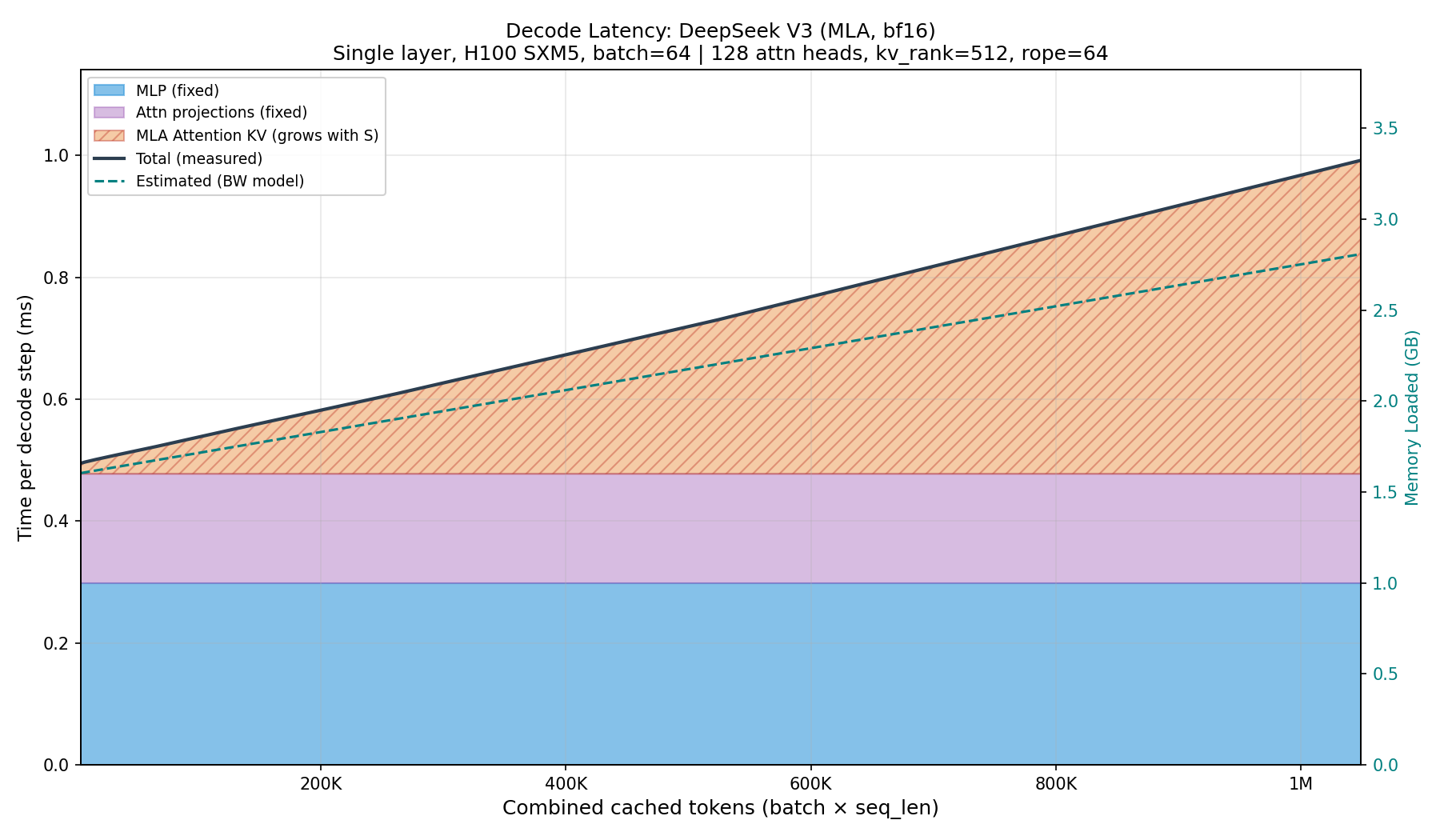
When we run these computations in real life, we observe a curve closely resembling this shape, as demonstrated in Fig. 16. We again fix the batch size at 64 and scale the sequence length. As with the GQA benchmark (Fig. 10), this is for a single transformer layer - in a full model the pattern repeats across all layers. Note that DeepSeek V3 uses MoE rather than the dense MLP we benchmark here; for the sake of simplicity we use a dense MLP as a proxy.
DeepSeek Sparse Attention
MLA was the first attention mechanism breakthrough introduced by DeepSeek, but not the last one. In September 2025, with DeepSeek-V3.2-Exp, they introduced DeepSeek Sparse Attention (DSA). The technique is described in the DeepSeek V3.2 tech report and shares the core idea of using lightweight attention heads for token selection with Native Sparse Attention (NSA), a concurrent work from overlapping authors. DSA is built on top of MLA - the core attention mechanism stays the same, DSA just adds a selection step before it. In principle, the same idea should work with standard attention mechanisms.
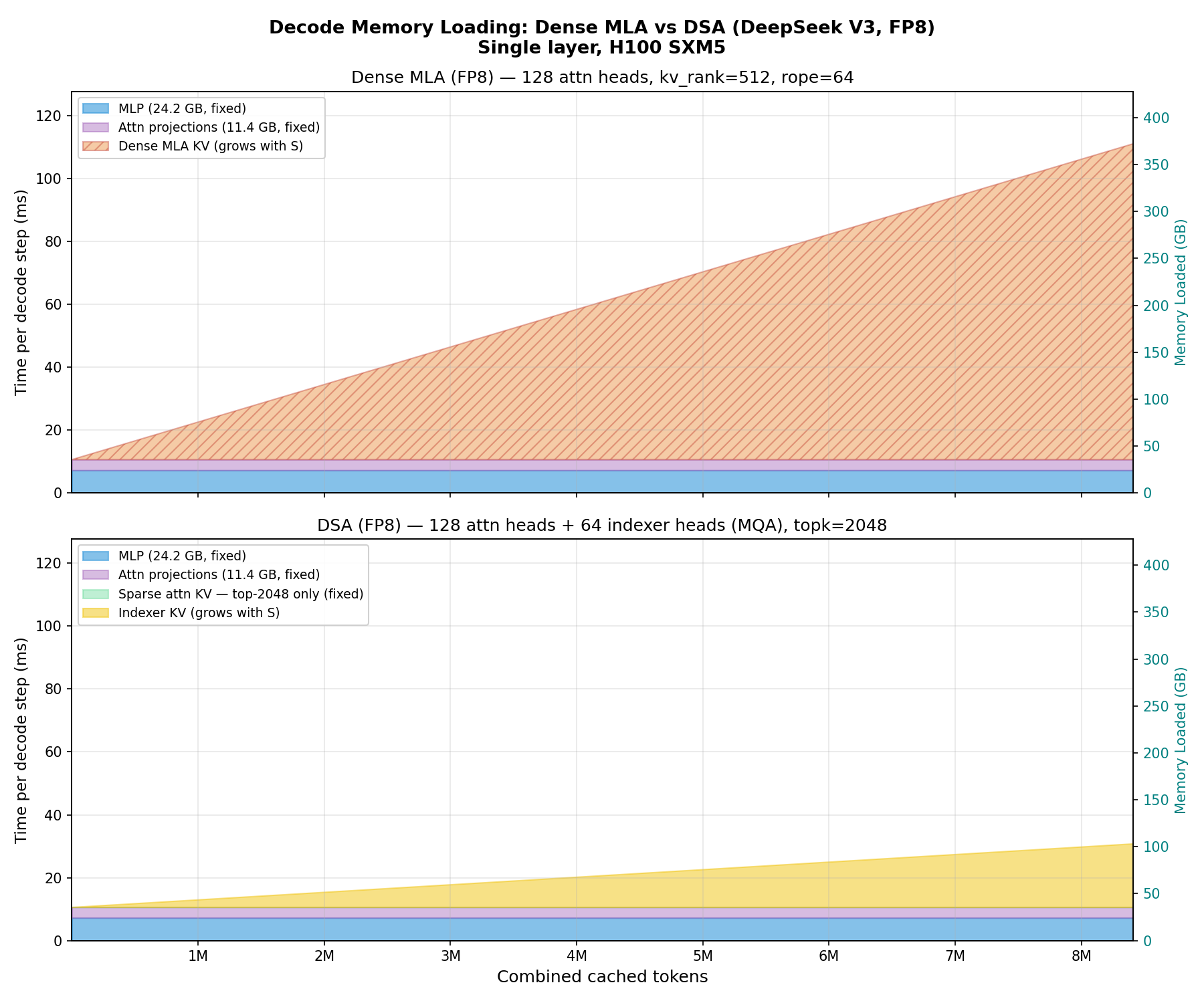
Recall from the previous section that MLA dramatically compressed the KV cache (Eq. 12) - from 4.0 MB per token (MHA) down to 70 KB per token (bf16) or 35 KB per token (FP8). This was a 57× reduction. And yet, as we showed in Figure 15, even with this compression the KV cache still grows linearly with the number of cached tokens. At long enough contexts, it once again dominates the memory loading.
The insight behind DSA is: do we really need to attend to all past tokens? What if we could cheaply figure out which tokens matter, and only attend to those?
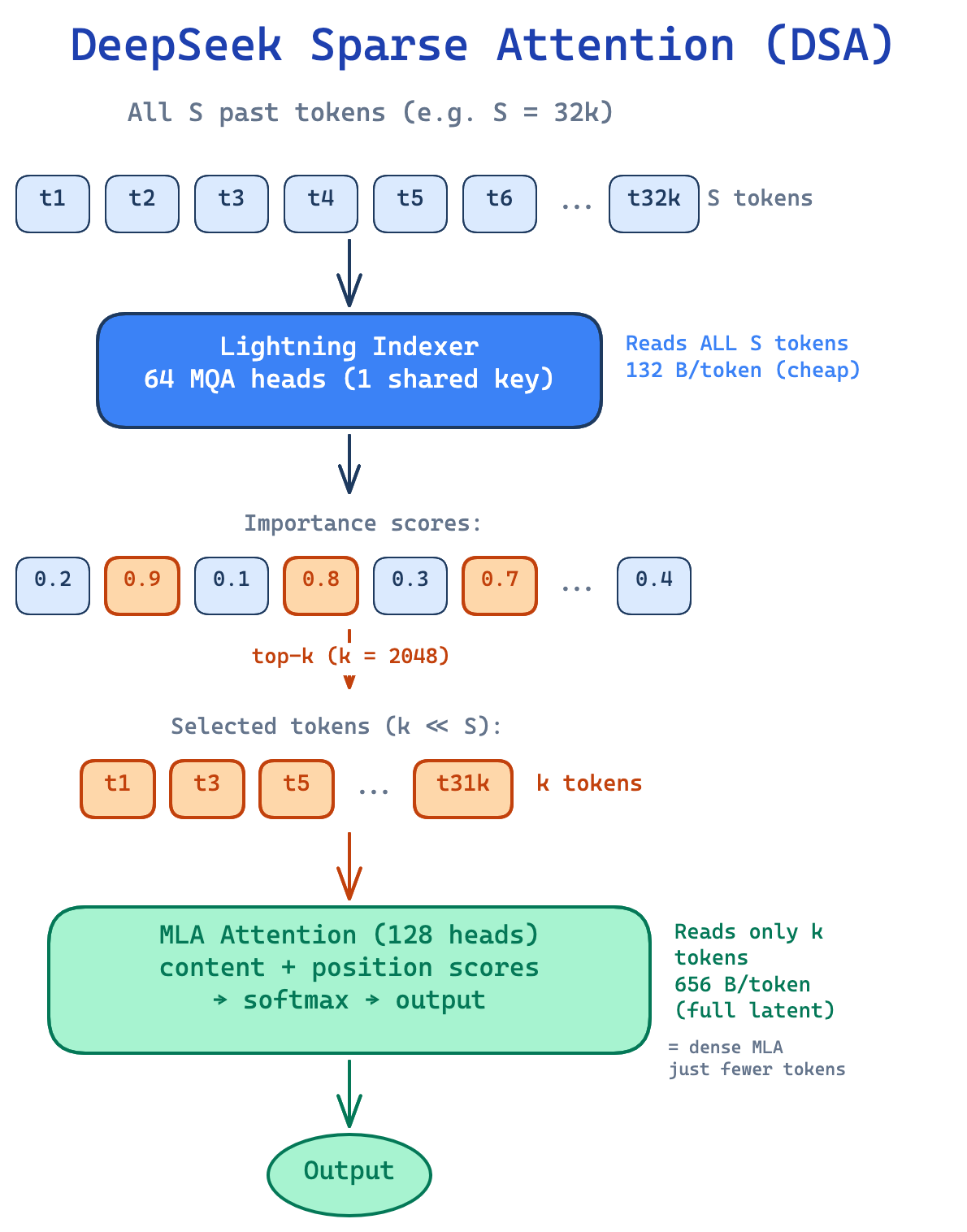
This is exactly what DSA does (Fig. 17). It introduces a lightning indexer - a small set of lightweight attention heads that score all past tokens and pre-select the k most important ones. Then the proper, expensive MLA attention is computed only over these k selected tokens.
The indexer is designed to be cheap. It uses MQA (a single shared key across all 64 heads), so its KV cache is tiny. It only computes dot-product scores - no full attention, no values. The indexer score for how relevant past token s is to the current query token t (see Fig. 17) is:
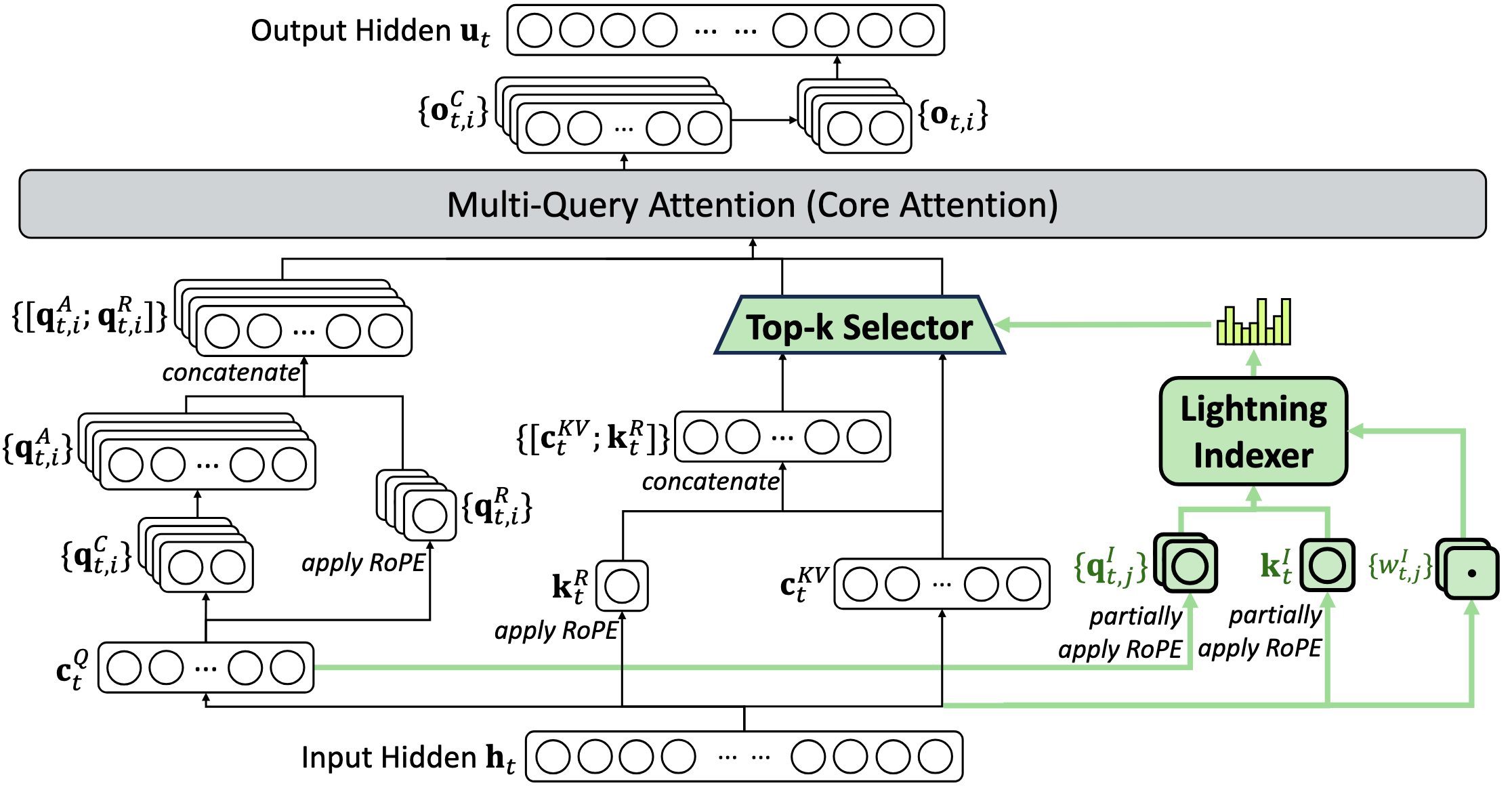
Each of the 64 indexer heads computes a dot product between its query and the single shared key, applies ReLU (so only positive contributions count), and the results are combined via learned weights into one score per past token. The top-k scoring tokens are then selected, and standard MLA attention runs only over these k tokens - identical to dense MLA (Fig. 13), just with fewer KV entries. The full architecture is shown in Figure 18.
Memory savings
Let’s calculate how much data DSA needs to load during decode compared to dense MLA. In the SGLang implementation, the indexer uses H_I = 64 heads with key dimension d_I = 128, and the default k = 2048.
Note that in the previous sections we calculated KV cache sizes in bf16 (2 bytes per element). From here on we switch to FP8 - the production DSA kernels (both the indexer and the sparse attention) operate in FP8, and to make a fair comparison we benchmark the dense MLA baseline in FP8 as well.
Dense FP8 MLA reads the full compressed latent for every cached token. Each token stores kv_lora_rank + qk_rope_head_dim = 576 elements. In practice, SGLang stores slightly more than 576 bytes because not all components use FP8:
512 bytes - compressed latent (NoPE) in FP8
16 bytes - FP8 per-block scale factors (4 × float32, block size 128)
128 bytes - RoPE key in bf16 (positional embeddings need higher precision)
This gives 656 bytes per token per layer, and we must read all N tokens:
DSA has two separate KV caches to read. First, the indexer KV cache. A key reason the indexer is so cheap is that it only stores keys, not values - it does not compute full attention, it only computes dot-product scores to rank which past tokens are important. Furthermore, it uses MQA: a single shared key of dimension d_I = 128 across all 64 query heads. SGLang allocates the indexer buffer as:
128 bytes - single MQA key in FP8
4 bytes - FP8 per-block scale factor (1 × float32, block size 128)
This gives 132 bytes per token per layer - 5x less than what dense MLA stores per token. The indexer KV must be read for all N tokens:
Second, the sparse attention KV cache. This stores the same 576-element MLA latent (656 bytes in mixed precision, as above). But crucially, we only read this for the k selected tokens:
This is a fixed cost - it does not grow with N.
An important subtlety: DSA does not reduce KV cache storage - we still store all N tokens in GPU memory (the indexer needs to be able to score any past token, and the selected set changes every step). What DSA reduces is the amount of data read from HBM per forward pass. Since decode is memory-bandwidth bound, this is what determines the wall-clock time.
Putting it together for all L = 61 layers at N = 131K context (Tab. 9):

The key asymmetry: the indexer reads all N tokens but at 132 bytes each (5x cheaper per token than dense MLA). The sparse attention reads the full 656 bytes per token - but only for a fixed k = 2048 tokens regardless of context length. At 131K, DSA loads ~5x less data than dense MLA per decode step. Fig. 19 visualizes how these costs scale with context length.
Real-world performance
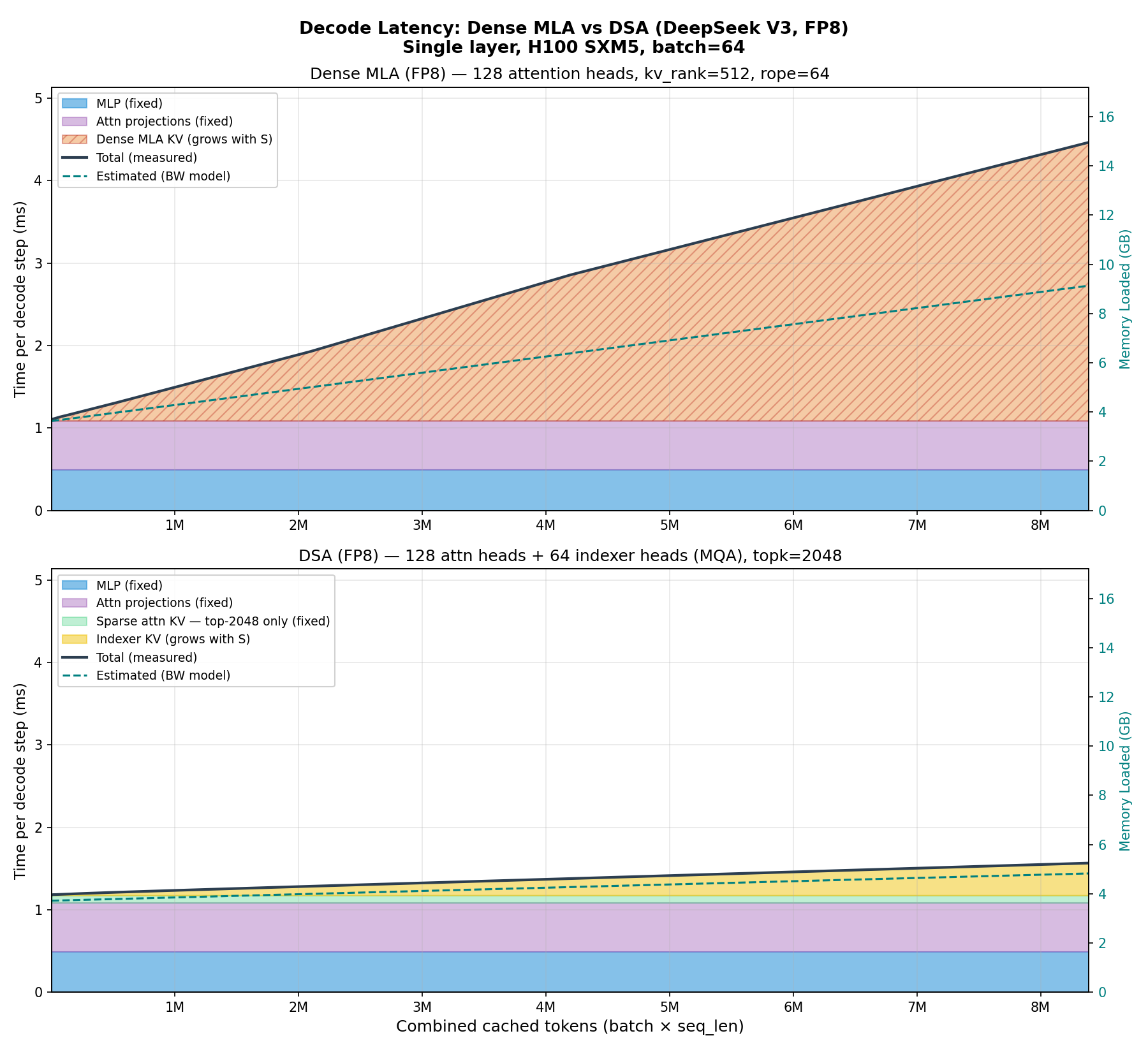
This is not just a theoretical argument. In Figure 20 we fix the batch size at 64, scale the sequence length, and measure decode latency for a single transformer layer using DeepSeek V3 dimensions. The pattern matches what we would expect from the memory analysis: the dense MLA attention cost grows linearly with context length, while DSA’s cost grows much more slowly - the sparse attention component is flat, and only the indexer grows with N.
Implications for MoE serving
Note that our memory loading charts above assume a dense MLP, but DeepSeek V3 uses Mixture of Experts (MoE). In DeepSeek’s production setup, each GPU manages only 2 routed experts and 1 shared expert - far smaller than the dense MLP we benchmarked. This means the MLP weight cost per forward pass is significantly smaller than what our charts show, making KV cache the dominant cost even earlier. In other words, the real-world case for DSA’s bandwidth savings is stronger than our dense-MLP figures suggest.
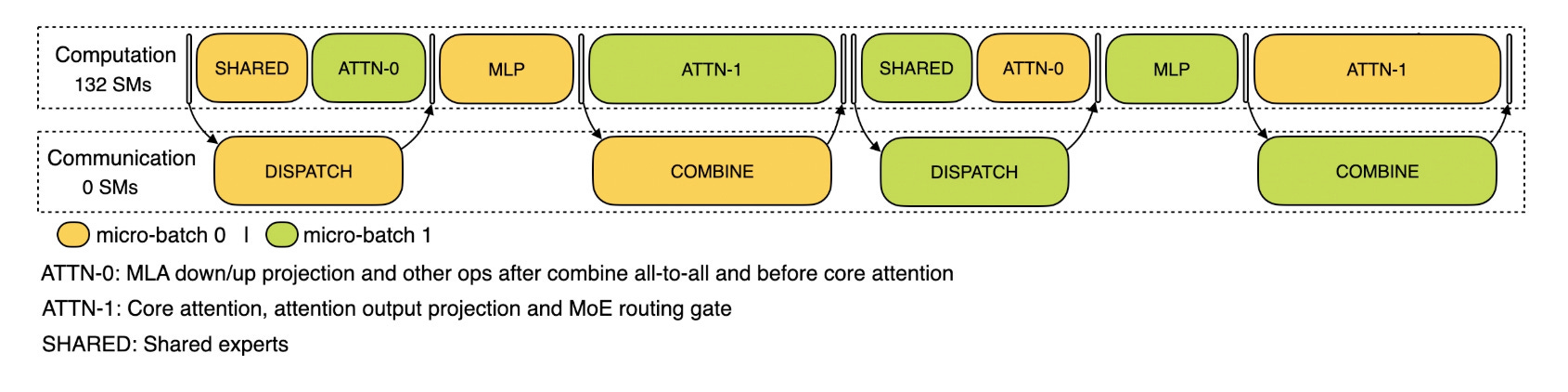
Beyond the raw speedup, DSA has an important implication for production MoE serving. Each GPU only holds a fraction of the experts, so at each layer tokens must be dispatched to the GPU that holds their assigned expert - requiring all-to-all communication. DeepSeek hides this cost using a dual micro-batch overlap: while one micro-batch computes, the other handles expert communication (see Figure 21). For this overlap to be efficient, the system needs to predict how long each computation phase will take. With dense MLA, the attention time varies wildly depending on the context lengths in the current batch - making it hard to design a reliable overlap schedule. DSA makes the per-layer computation time nearly constant regardless of context length (Eq. 16 - the sparse attention reads a fixed k tokens), which makes the overlap mechanism much easier to design and reason about in practice.
Minimal DSA Decode Implementation
In Fig. 22 we present a minimal implementation of DSA decode, building on the MLA decode (MQA mode) implementation above. As with MLA, prefill uses the MHA mode - reconstructing full K/V and running flash attention, with DSA adding its indexer on top (see Appendix for the prefill benchmark). The key addition for decode is the lightning indexer - a lightweight scoring mechanism that selects which tokens to attend to. The implementation highlights three properties:
The indexer uses MQA (❶): a single shared key across all 64 indexer heads, which is why its KV cache is so small (132 bytes/token in FP8 vs 576 bytes/token for dense MLA).
No values in the indexer (❷): the indexer only computes dot-product scores to rank tokens - it never does full attention.
Sparse attention is fixed-cost (❸): regardless of context length, the MLA attention kernel always processes exactly k tokens.
Note how the KV cache now stores three components: the MLA compressed latent c_kv, the RoPE key k_rope, and the indexer key idx_k. During decode, the indexer scores all S tokens but only reads its small MQA keys (132 bytes/token in FP8). The MLA attention then runs over exactly topk tokens - a fixed cost regardless of how long the context grows. This is the source of DSA’s near-constant decode time.
MLA/DSA is edge-hardware friendly
A common concern with novel attention mechanisms is that they require custom GPU kernels to be practical. This is true for many architectures - writing efficient Metal, Vulkan, or even CUDA kernels is hard, and the lack of kernel support can make a mechanism unusable on edge devices like phones or laptops.
MLA (and by extension DSA) sidesteps this problem entirely. The absorption trick we described above reshapes the computation so that the decode path is just standard scaled_dot_product_attention - no custom kernel needed. This is nicely demonstrated in Fig. 23 from the MLX implementation of DeepSeek V3:
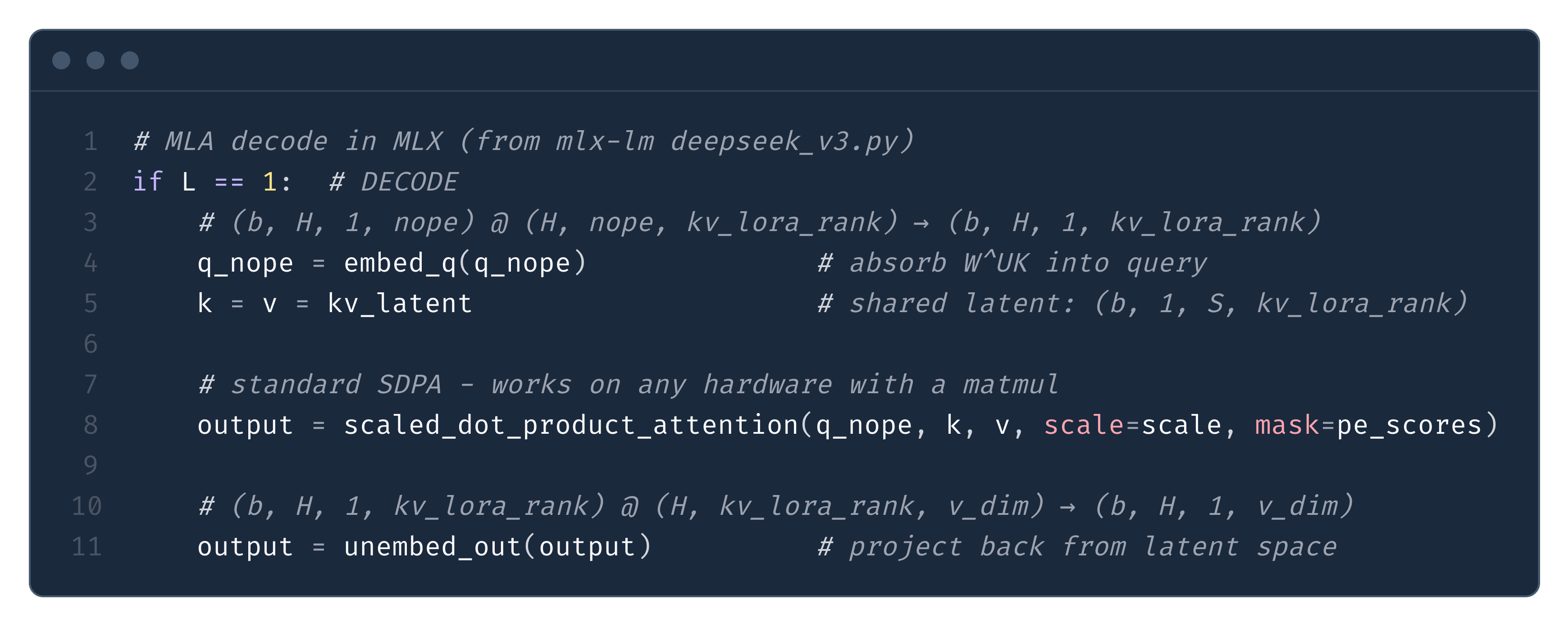
The key insight is that absorption converts MLA into something that structurally resembles MQA - all 128 heads share the same compressed “key” and “value” (kv_latent), and the per-head differentiation happens entirely through the query. Any framework that supports broadcasting in SDPA (PyTorch, MLX, JAX) handles this natively.
DSA adds one extra step - a gather before SDPA - which is equally portable (Fig. 24). From the MLX implementation of DeepSeek V3.2:
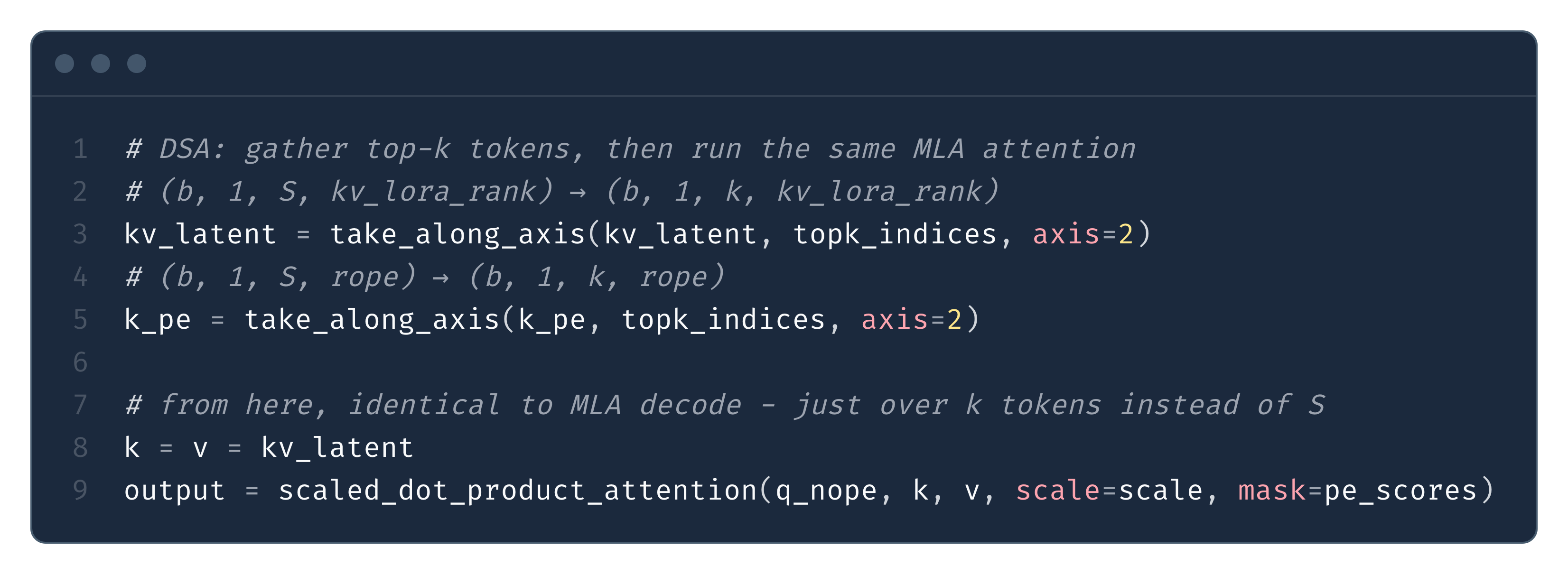
Of course, production GPU kernels are significantly faster. FlashMLA fuses the two-path scores, causal mask, and attention into a single kernel. SGLang’s sparse DSA kernel fuses the gather into the attention loop, loading selected KV entries directly from HBM to SRAM without materializing an intermediate tensor. But the important point is that none of this is required - the naive SDPA path gives full correctness, full 57× KV cache compression, and the full absorption speedup, on any hardware that can do a matrix multiply.
From FLOPs to dollars
The key intuition we hope the reader gets after reading this text is that the main benefit of DSA is that as the sequence length grows, the memory footprint grows much slower (close to constant) compared to standard attention mechanism or MLA, resulting in massively improved economics of serving long-context models.
Long context is crucial for the most profitable domain of LLMs - coding assistants. DSA is the kind of architecture innovation that makes “Claude Code-like” products viable commercial projects, with positive gross margins rather than interesting demos. As SORA’s shutdown showed us, cheap economics of model serving is critical for the commercial viability of an AI product. One can have the best model capable of superhuman performance, but if the GPU math doesn’t math it won’t work as a commercial project.
Introduction of DSA enabled DeepSeek to massively reduce the price of inference (see Fig. 2), fuelling the intelligence involution and driving down prices for other players in the space. DSA adoption seems rather slow in the industry, with one notable exception - Z.ai. The GLM5 (and its successor GLM5.1), released in 2026, utilize DSA. GLM is widely acknowledged as the leading open-source model (see Fig. 25), providing capability second only to Anthropic, Google and OpenAI (on benchmarks). The adoption of DSA by GLM5/5.1 suggests that sparse attention can be a viable alternative to standard attention.
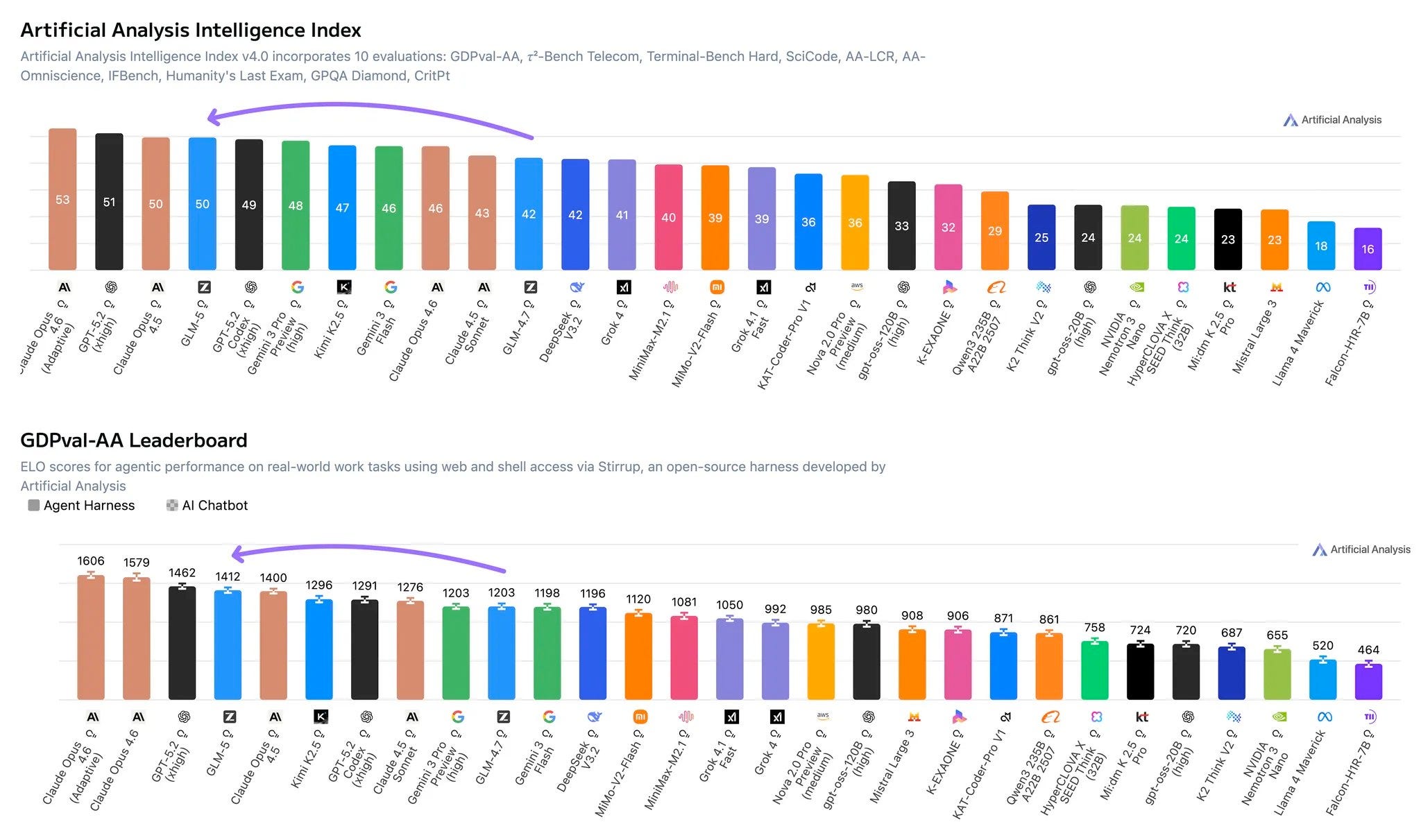
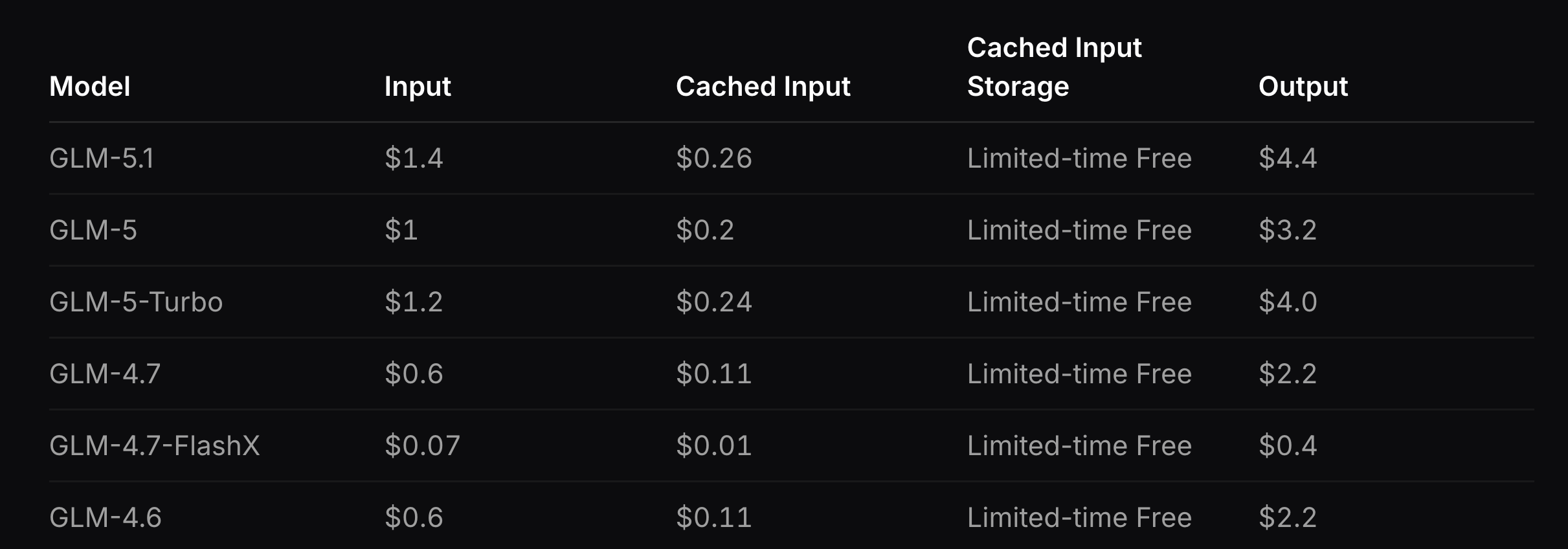
Interestingly, Z.ai’s API pricing does not pass through the efficiency gains from DSA. GLM5.1 output tokens are noticeably more expensive than GLM 4.7, and pricing has only increased with the 5.0 → 5.1 transition (see Fig. 26), despite the architectural savings from sparse attention. Part of this is justified - GLM5/5.1 has more active parameters per forward pass - but the DSA savings at long context are substantial. We interpret the higher prices and lower serving costs as a deliberate margin play: as a publicly traded company, Z.ai appears to be capturing the serving efficiency as profit rather than passing the savings onto the consumer. We expect this trend to continue - further price increases and potentially more restrictive licensing (similar to Minimax’s non-commercial license) with future releases, as the company targets significantly higher gross margins to justify the compute investment needed for next-generation of models.
DSA is the key enabler of serving models cheaply at long context - a property required for any “Claude Code-like” coding assistant. Z.ai seems to be positioning the GLM Coding Plan as a key export-oriented service, a sticky product rather than a cheap commodity - one that can support revenues for the compute buildup needed for the next generation of models. Long context is of paramount importance for such a service, and DSA unlocks it. We are looking forward to the H1 2026 interim results for confirmation of this thesis.
Note: this is not investment advice. Readers should be aware that Zhipu AI is on the US Entity List, which restricts US exports to the company and may affect its long-term access to advanced hardware.
Alongside prefill caching and RLM-like scheduling of subagents to conduct sub-tasks on behalf of the main model, processing long context at scale is crucial for viability of any “Open-Claw-like” product. DSA provides the first example of a viable sparse attention mechanism that is actually working in a model at the bleeding edge. DeepSeek Sparse Attention is just the beginning - we know it works up to a 1M context window but there is no reason to believe it can’t scale further.
As we have seen in Fig. 28 for prefill and Fig. 20 for decode, the indexer becomes the bottleneck at long contexts - scaling O(S²) during prefill and O(S) during decode. There are already promising approaches to address this. GLM showed that the indexer can be shared across multiple layers, amortizing the cost. HISA takes a different approach, replacing the flat token scan with a hierarchical two-stage indexer that achieves 3.75x speedup at 64K as a training-free drop-in replacement.
Since coding agents seem to be the LLM product, there is enormous pressure on companies to improve upon sparse attention mechanisms. This, combined with how affordable it is to train - e.g. the GLM paper trains the indexer on just 20B tokens - makes us confident that DSA-like mechanisms will unlock cheap long context at the scale of millions of tokens.
One additional note: in principle, nothing prevents applying the indexer mechanism to standard attention rather than MLA. We are not aware of anyone who has tried this yet, but the sparse selection idea is orthogonal to how K and V are stored.
To sum up, we went from standard multi-head attention (MHA), through group query attention (GQA), to multi-head latent attention (MLA). We showed how the gains in each come from reducing the size of the KV cache - during the forward pass we load less data from HBM, decreasing the latency and as a result the cost of producing a token. Then we showed how DeepSeek Sparse Attention (DSA) works, examined where the savings come from, and demonstrated that this is not just a theoretical model but something observable in practice. Last but not least, we speculated on the effects of sparse attention on the economics of coding models.
Appendix
MLA Prefill: Why Absorption Doesn’t Help
The absorption trick makes decode fast - but should we use it during prefill too? The answer is no! The reason is quite simple: absorption trades smaller KV cache loading (good for memory-bound decode) for larger attention FLOPs (bad for compute-bound prefill).
During prefill there is no KV cache - we compute everything from scratch. Two options, using DeepSeek V3 dimensions: qk_nope_dim = 128, qk_rope_dim = 64, v_dim = 128, kv_lora_rank = 512, num_heads = 128.
Option 1: Reconstruct K/V (MHA mode - what real systems do). Decompress C^KV into full per-head K and V, then run standard flash attention. Each head operates on small per-head_dimensions:
where 192 = qk_nope_dim + qk_rope_dim = 128 + 64.
Per head: 2 S^2 (192 + 128) = 2 S^2 320. Across all 128 heads:
Option 2: Absorb (MQA mode - hypothetical for prefill). Skip reconstructing K/V. Instead absorb W^UK into Q (as we do in decode) and attend directly to the compressed latent C^KV. Each head now operates in the 512-dim latent space:
Per head: 2 S^2 (512 + 64 + 512) = 2 S^2 1,088. Across all 128 heads:
The absorbed form is 3.4x more expensive (278,528 / 81,920 = 3.4). The core reason: in MHA mode each head attends in 192 dimensions (qk_nope_dim + qk_rope_dim). In MQA mode each head attends in 512 dimensions (kv_lora_rank) - the content path alone is 4x wider, and the value weighted sum also runs in 512 dims instead of 128. The projection costs are identical in both cases, so the S^2 attention term dominates at long sequences.
Since prefill is compute-bound, there is no sequence length where absorption wins for prefill. This is why SGLang (and all production engines) use MHA mode for prefill and MQA mode for decode.
Below is a minimal MLA prefill implementation matching this approach (Fig. 27):
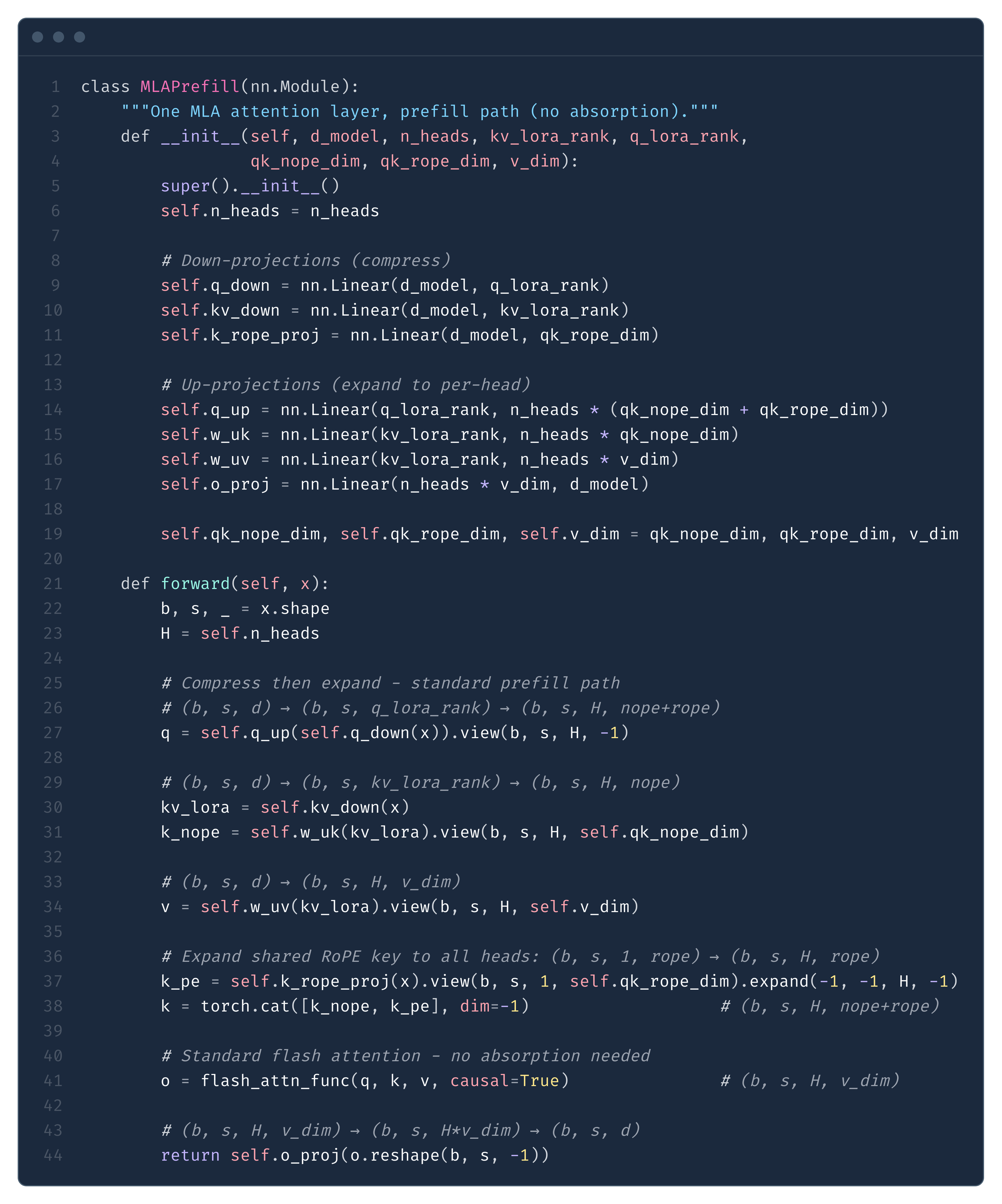
w_uk and w_uv and runs standard flash attention. This avoids the 3.4x FLOP penalty of absorption (see text above).Note: in SGLang, q_down/kv_down/k_rope_proj are fused into one matrix (fused_qkv_a_proj_with_mqa), and w_uk/w_uv into one (kv_b_proj). RMSNorm is applied to compressed latents before up-projection, and RoPE to q_pe/k_pe. Omitted for clarity.
DSA Prefill Benchmark
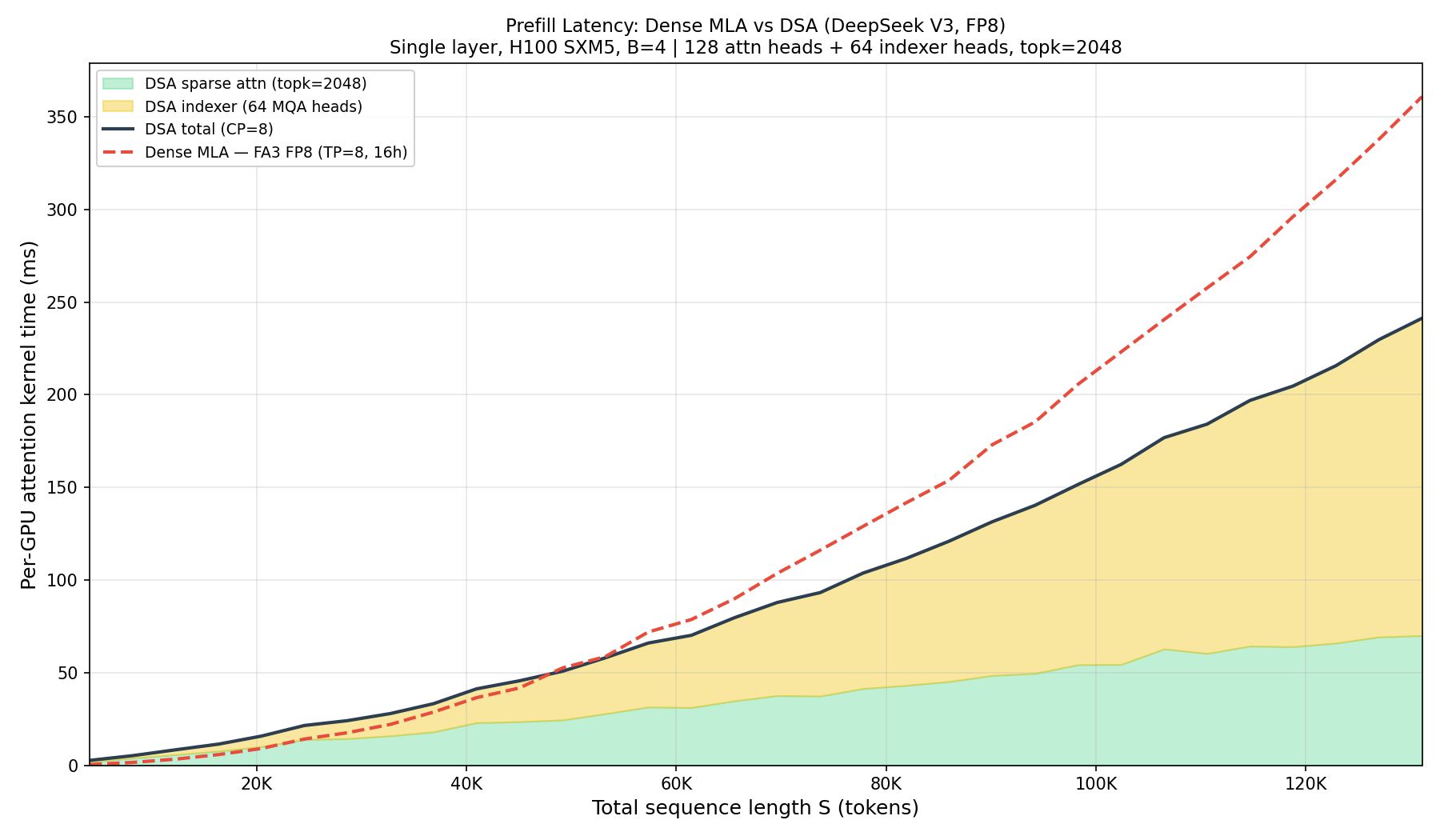
How does DSA change the prefill picture? DeepSeek’s own estimates (Fig. 1) show prefill cost growing linearly with DSA vs quadratically for dense MLA. In Figure 28 we attempt to reproduce this, comparing per-GPU prefill attention time for V3 (FA3 with tensor parallelism TP=8, 16 heads per GPU) against V3.2 DSA (context parallelism CP=8, all heads but S/8 query tokens per GPU). We use CP for DSA because the indexer can’t be split across GPUs - it needs all heads to produce a single top-k mask.
We were not fully able to replicate DeepSeek’s numbers. At short sequences DSA is actually slower than dense FA3 due to fixed overhead from the indexer and sparse kernel. DSA only pulls ahead beyond ~40K tokens, reaching 1.5x speedup at 128K. DeepSeek’s figure shows a cleaner crossover - likely reflecting differences in their production setup that we cannot reproduce with public kernels.
Note that unlike decode (where sparse attention is truly fixed-cost), during prefill both DSA components grow with S. The sparse attention grows linearly (O(S/CP × topk)), but the indexer grows quadratically (O(S²/CP)) - same scaling as FA3. DSA still wins because the indexer uses lightweight MQA heads (single shared key, 128-dim) which are much cheaper per operation than FA3’s full multi-head attention.
Acknowledgments
Thanks to Szymon, Pieter, Eric and Lukas for proofreading and pushing back on the parts I was confident about but shouldn’t have been.
@online{tensoreconomics2026dsa,
author = {Piotr Mazurek},
title = {DeepSeek Sparse Attention from First Principles},
url = {https://www.tensoreconomics.com/p/deepseek-sparse-attention-from-first},
urldate = {2026-04-15},
year = {2026},
month = {April},
publisher = {Substack}
}